


Lịch sử Deep Learning (DL)
Ngày đăng: 20/03/2024
Trước sự phát triển vượt bậc đó, Deep Learning hứa hẹn sẽ mang lại những thành quả bất ngờ và những bước tiến của nó sẽ ảnh hưởng sâu rộng hơn đến cuộc sống của mỗi người trong xã hội hiện đại. DL mang đến một thời đại mới với cuộc cách mạng cũng nó cũng như đặt ra các thách thức cho mỗi người để không bị thay thế.
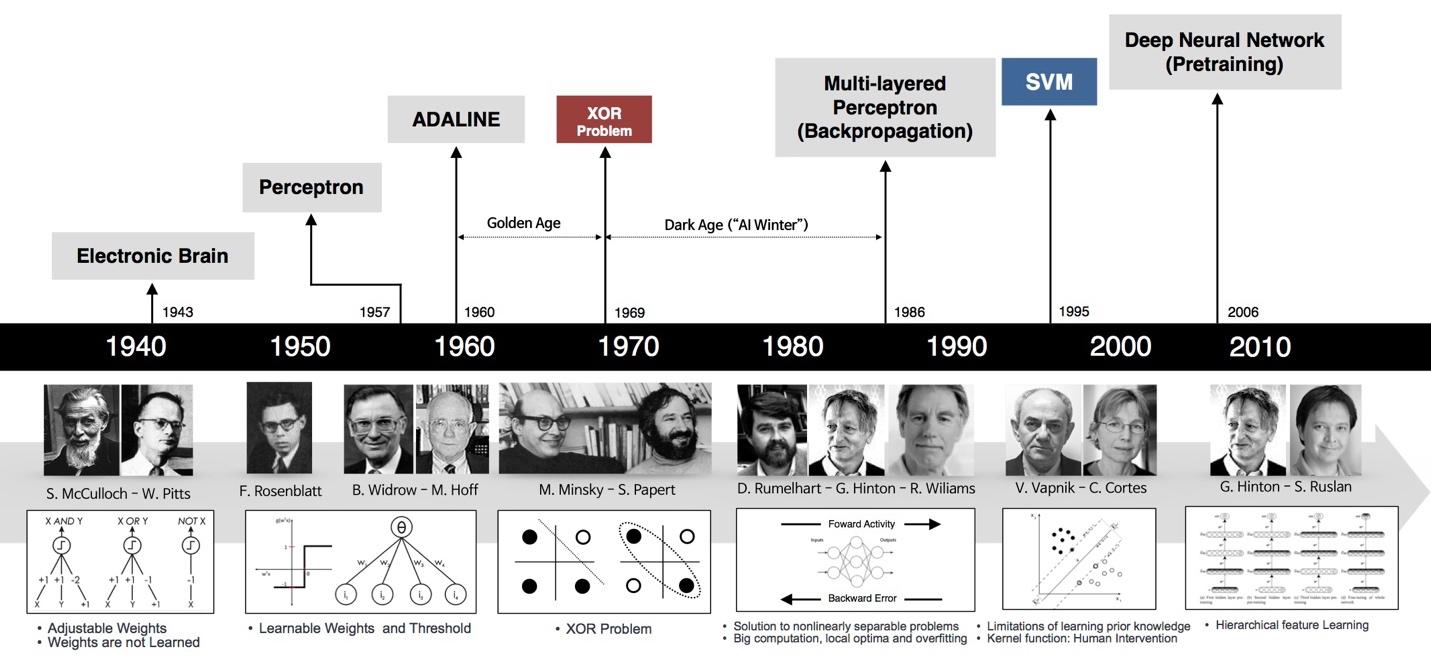
Lịch sử deep learning (Hình được lấy từ Deep Learning 101 - Part 1: History and Background)
I. Giới thiệu
Ngày nay, Aritificial Intelligence (AI - trí tuệ nhân tạo) và Machine Learning (ML – học máy) hiện diện trong mọi lĩnh vực của đời sống con người, từ kinh tế, giáo dục, y khoa cho đến những công việc nhà, giải trí hoặc thậm chí là trong quân sự. Những ứng dụng nổi bật trong việc phát triển AI đến từ nhiều lĩnh vực để giải quyết nhiều vấn đề khác nhau. Nhưng những đột phá phần nhiều đến từ Deep Learning (DL - học sâu) - một mảng nhỏ đang mở rộng dần đến từng loại công việc, từ đơn giản đến phức tạp.
Qua bài viết này, chúng ta hãy cùng xem lại một cách nhanh chóng quá trình phát triển của DL từ những hiểu biết đơn giản nhất cho đến thời kỳ hoàng kim như ngày hôm nay.
II. Những khái niệm đầu tiên
1. Khởi nguồn từ toán học (1763 - 1940)
Năm 1763, một bài luận về xác suất của Thomas Bayes được xuất bản 2 năm sau khi ông qua đời, lúc đó ít ai quan tâm đến nó. Gần nửa thế kỷ sau, vào năm 1812 nó được nhà toán học Laplace hợp thức hóa thành lý thuyết xác suất mà ngày nay chúng ta gọi là Định lý Bayes, cốt lõi của mạng Bayes hay Belief Network, là một trong những cấu trúc đóng góp lớn đến thành công của DL ngày nay (Deep Belief Network).
Năm 1805, lý thuyết về Least Squares ra đời, thời đó được sử dụng trong thiên văn và trắc địa, không ai biết được ngày nay nó là hàm loss cơ bản nhất của Artificial Neural Network (ANN).
2. Ý tưởng khoa học cho một chiếc máy “giống người” (1943 - 1967)
Năm 1943, nhà thần kinh học Warren McCulloch và nhà toán học Walter Pitts công bố “A logical calculus of the ideas immanent in nervous activity”. Nghiên cứu này tìm hiểu cách não bộ con người có thể tạo ra các mẫu phức tạp thông qua các tế bào não kết nối, hay còn gọi là nơ-ron. Một trong những ý tưởng chính được đưa ra từ công việc này là so sánh giữa nơ-ron với ngưỡng nhị phân và logic Boolean (tức là câu lệnh 0/1 hoặc đúng/sai). Họ cũng đã tiến hành xây dựng một mạng neural đơn giản bằng các mạch điện, các neural của họ được xem như là các thiết bị nhị phân với ngưỡng cố định. Kết quả của mô hình này là các hàm logic đơn giản.
Như vậy ý tưởng về mạng neural nhân tạo (artificial neural networks) xem như đã được xuất hiện từ đây. Mạng nơ-ron nhân tạo là tiền thân của học sâu (deep learning) đang rất phổ biến hiện nay.
Năm 1950, lấy cảm hứng từ việc con người thực hiện các công việc bình thường như thế nào, Alan Turing định hình nên ý niệm của ông về một Universal Machine (máy toàn năng). Sau nhiều năm nghiên cứu, ông công bố bài báo của mình “Computing Machinery and Intelligence” dưới dạng một bài luận cùng với một ý tưởng về bài kiểm tra cho một chiếc máy mô phỏng con người: Turing Test.
Có lẽ, ông không biết rằng, 60 năm sau khi ông mất, những AI đã bắt đầu passed qua bài Test.
Rosenblatt's Perceptron, 1957
Một trong những nền móng đầu tiên của neural network và deep learning là perceptron learning algorithm (hoặc gọn là perceptron). Ý tưởng về Perceptron hoạt động dựa trên cấu trúc tế bào thần kinh trong não bộ con người, lần đầu tiên được công bố, khi đó nó bao trùm cả truyền thông về một tương lai tươi sáng sắp tới gần của AI.

Frank Rosenblatt (người bên phải)
Nguồn ảnh: https://slides.com/beamandrew/deep-learning-101/#/14
Năm 1956, Cụm từ “Artificial Intelligence” lần đầu tiên được nói đến tại hội nghị “Dartmouth Summer Research Project on Artificial Intelligence” bởi nhà khoa học máy tính người Mỹ, John McCarthy. Với sự dẫn đầu của ông thì hội nghị đã xác định phạm vi và mục tiêu của AI, sự kiện này được coi là sự ra đời của trí tuệ nhân tạo như chúng ta biết ngày nay.
Năm 1959, Arthur Samuel đưa ra khái niệm “Machine Learning”. Ông báo cáo về việc lập trình một máy tính “để nó học cách chơi một ván cờ caro tốt hơn những gì người viết chương trình có thể chơi”
3. Phản biện và hoài nghi (1969 - 1981)
Mặc dù thuật toán Perceptron mang lại nhiều kỳ vọng nhưng nó nhanh chóng được chứng minh không thể giải quyết những bài toán đơn giản.
Năm 1969, Marvin Minsky và Seymour Papert trong cuốn sách nổi tiếng Perceptrons đã giới thiệu cho độc giả về những giới hạn của Perceptron, trong đó nhấn mạnh việc Perceptron không thể học cách biểu diễn hàm XOR. Phát hiện này làm choáng váng giới khoa học thời gian đó (bây giờ chúng ta thấy việc này khá hiển nhiên). Hơn nữa, họ còn chứng minh rằng Perceptron là không thể học các hàm phi tuyến được vì giá trị của nó chỉ dựa trên bộ dữ liệu tuyến tính (linearly separable.).
Phát hiện này khiến cho các nghiên cứu về perceptron bị gián đoạn gần 20 năm. Thời kỳ này còn được gọi là Mùa đông AI thứ nhất (The First AI winter).
III. Trở nên thực tế hơn
1. Backpropagation ra đời (1982 - 1988)
Geoffrey Hinton tốt nghiệp PhD ngành neural networks năm 1978. Năm 1986, ông cùng với hai tác giả khác xuất bản một bài báo khoa học trên Nature với tựa đề “Learning representations by back-propagating errors”. Trong bài báo này, bằng việc tổng quát hóa AutoDiff của Seppo thành một thuật toán thì nhóm của ông chứng minh rằng neural nets với nhiều hidden layer (được gọi là multi-layer perceptron hoặc MLP) có thể được huấn luyện một cách hiệu quả hơn dựa trên một quy trình đơn giản được gọi là backpropagation

David Rumelhart, Geoffrey Hinton, Ronald J. Williams
Thuật toán này mang lại một vài thành công ban đầu, nổi trội là convolutional neural nets (convnets hay CNN) (còn được gọi là LeNet) cho bài toán nhận dạng chữ số viết tay được khởi nguồn bởi Yann LeCun tại AT&T Bell Labs (Yann LeCun là sinh viên sau cao học của Hinton tại đại học Toronto năm 1987-1988).
Sự kiện Yann LeCun đã tạo ra LeNet5, được xem là CNN đầu tiên được hiện thực hóa, giúp ông được coi là nhân vật quan trọng trong sự phát triển của DL ngày nay.
2. Học với con người (1989 – 1994)
Con người chúng ta học không phải theo cách của ANN, mỗi người đều vừa học vừa làm, có khi còn tự học. AI là mô phỏng lại khả năng của con người, vậy tại sao chúng cũng không làm như vậy?. Và thế là Reinforcement Learning (RL – học tăng cường) được phát minh ra năm 1989. Thực tế, đó là sự mô mình hóa bằng toán học quá trình học tập của con người, một điều không hề đơn giản. Q-learning chính là kết quả của nhiều năm nghiên cứu để đưa RL trở nên thực tế hơn, đơn giản hơn của Christopher Watkins. Đó còn là một dấu hiệu cho tương lai của những AI chơi game đang đến gần.
3. Giới hạn và đình trệ (1995 – 2001)
Mùa đông AI thứ hai (90s - đầu 2000s)
Các mô hình tương tự được kỳ vọng sẽ giải quyết nhiều bài toán image classification khác. Tuy nhiên, không như các chữ số, các loại ảnh khác lại rất hạn chế vì máy ảnh số chưa phổ biến tại thời điểm đó. Ảnh được gán nhãn lại càng hiếm. Trong khi để có thể huấn luyện được mô hình convnets, ta cần rất nhiều dữ liệu huấn luyện. Ngay cả khi dữ liệu có đủ, một vấn đề nan giải khác là khả năng tính toán của các máy tính thời đó còn rất hạn chế.
Một hạn chế khác của các kiến trúc MLP nói chung là hàm mất mát không phải là một hàm lồi. Việc này khiến cho việc tìm nghiệm tối ưu toàn cục cho bài toán tối ưu hàm mất mát trở nên rất khó khăn. Một vấn đề khác liên quan đến giới hạn tính toán của máy tính cũng khiến cho việc huấn luyện MLP không hiệu quả khi số lượng hidden layers lớn lên. Vấn đề này có tên là vanishing gradient.
Nhiều nhà khoa học làm machine learning chuyển sang nghiên cứu SVM trong thời gian đó. Những công cụ AI khác dần phát triển, nổi bật nhất chính là Monte Carlo Tree Search (MCTS), cốt lõi của DeepBlue, AI đầu tiên đánh bại đại kiện tướng Garray Kasparov năm 1997. Tuy gọi là DeepBlue như thế nhưng thực ra là để thể hiện khả năng tìm kiếm nhanh chóng, độ sâu cao của MCTS trong đó chứ không liên quan đến DL.
IV. Khoảng lặng
1. Củng cố nền tảng (2002 - 2006)
Còn rất nhiều việc khác ngoài phát triển lý thuyết để tạo nên sự phát triển của DL mà chúng ta thấy ngày nay. Đây là quãng thời gian mà mọi thứ bắt đầu được chuẩn bị.
Bây giờ, chúng ta đều biết, để xử lý những vấn đề lớn một cách nhanh chóng thì hiển nhiên phải sử dụng những công cụ chất lượng cao, phải chứ? Không thể nào chúng ta có thể vẽ chính xác bản đồ của Trái Đất chỉ với bút chì và giấy bình thường được. Điều đó là tương tự với DL.
Trước hết, chúng ta cần một framework để những nhà nghiên cứu nhanh chóng thử nghiệm các ý tưởng của họ mà không phải quá tập trung vào các vấn đề liên quan đến kỹ thuật phần mềm (software engineering). Vậy là framework ML đầu tiên ra đời: Torch. Đây là framework viết bằng Lua interface với back-end là C, những vấn đề mà nó gặp phải đã trở thành những bài học quý báu cho các framework về sau như Tensorflow hay PyTorch.
Tuy nhiên, việc tạo ra các model tốt và việc model đó hoạt động tốt là hai thứ hoàn toàn khác nhau. Những nhà nghiên cứu muốn nhanh chóng thử nghiệm model của họ trên thực tế, họ cần phải có một công cụ tính toán hiệu quả, nhanh chóng. Đó là sự tăng tốc đến từ phần cứng, trong suốt quá trình phát triển thầm lặng của DL, ít ai hiểu rõ tầm quan trọng của phần cứng đối với hiệu quả thực tế của model. Bước ngoặt được tạo ra khi NVidia thiết kế thành công kiến trúc CUDA năm 2006, lúc đó họ chưa biết rằng hiệu quả từ kiến trúc này to lớn như thế nào. 10 năm sau, dòng GPU chuyên biệt hỗ trợ DL của NVidia chính thức ra mắt – Volta.
Cùng năm đó, giải thưởng Netflix được công bố cho những ai thiết kế Recommendation System (hệ thống đề xuất cho người dùng) với độ chính xác cao hơn họ 10%. Tuy cuộc thi đã kết thúc khi giải thưởng được trao năm 2009 nhưng nó đã làm tiền đề cho các cuộc thi AI quan trọng sau này, trong đó có Kaggle, nơi mà các team phát triển AI tranh đấu với nhau hiện nay.
2. Âm thầm tái xuất (2006 - 2008)
Cái tên được làm mới – Deep Learning (2006)
Trong suốt những năm đó, Hinton vẫn dày công tìm cách đưa ANN đến với thế giới thực. Năm 2006, Hinton một lần nữa cho rằng ông biết bộ não hoạt động như thế nào, và giới thiệu ý tưởng của tiền huấn luyện không giám sát (unsupervised pretraining) thông qua deep belief nets (DBN). DBN có thể được xem như sự xếp chồng các unsupervised networks đơn giản như restricted Boltzman machine hay autoencoders.
Với những kết quả nghiên cứu của ông, người ta đã có thể train những ANN sâu hơn, rộng hơn. Kể từ đây, neural networks với nhiều hidden layer được đổi tên thành deep learning, và DL trở thành một nhánh riêng biệt, tách khỏi ANN trong ML.
Cũng trong năm 2006 này, AI bắt đầu xuất hiện trong giới kinh doanh. Các công ty như Facebook, Twitter và Netflix bắt đầu sử dụng AI.
Kể từ năm 2013, không chỉ các nhà nghiên cứu mà cả các công ty công nghệ cũng bắt đầu chú ý đến DL. Trước năm 2009, Google phát triển một nền tảng DL (mặc dù lúc đó chưa được chú ý nhiều) gọi là DistBelief, dẫn đầu bởi chính Hinton, đóng vai trò quan trọng trong việc giảm thiểu lỗi của các hệ thống ML. Kể từ sau sự kiện 2012, Google đẩy mạnh đầu tư vào mảng này, chỉ định thêm các nhà khoa học máy tính để cải tiến nền tảng, cả về lý thuyết lẫn cấu trúc của source code. Cuối cùng, nó trở nên mạnh mẽ, nhanh chóng và gọn gàng hơn trước khi được đổi tên thành Tensorflow vào ngày 9/11/2015 dưới dạng open-source.
Tiếp theo sau đó, những DL framework khác lần lượt ra đời, phát triển, thậm chí chấm dứt vì sự cạnh tranh khốc liệt.
Năm 2014, Facebook công bố DeepFace của họ, công cụ mà cho đến tận bây giờ chúng ta vẫn dùng để tag lên hình ảnh của mình. Với 97.35% độ chính xác, DeepFace vượt mặt những đối thủ của nó. Thực tế thì nó đã gần đạt được độ chính xác của con người dù con số 2.65% error không phải là nhỏ. Tuy vậy, đây vẫn là một dấu hiệu báo trước ngày mà những hệ thống DL vượt qua khả năng của con người đã không còn xa: AlphaGo (Lee ver.) đánh bại đại kiện tướng cờ vây Lee Sedol 4-1 vào năm 2016, trở thành chương trình máy tính đầu tiên giành chiến thắng trước một kỳ thủ cờ vây chuyên nghiệp. Sự kiện này cho thấy một bước tiến to lớn trong gần 20 năm từ khi DeepBlue đánh bại Kasparov (không gian tìm kiếm và luật chơi cờ vây khó hơn cờ vua rất nhiều).
Trong năm 2017, DL liên tục gửi những bất ngờ đến với cả thế giới: OpenAI bot đánh bại Dendi, người chơi Dota 2 chuyên nghiệp tại The International 2017. Đáng chú ý hơn nữa AlphaGo (Zero ver.) đánh bại phiên bản trước đó (Lee ver.) mà không cần sự hướng dẫn của con người, chỉ tự chơi với chính nó (Lee ver. phải học từ các lượt chơi của con người, sau đó mới tự học). Và AlphaZero, được tổng quát hóa hơn AlphaGo, tự tìm ra cách chơi cờ vua và cờ shogi, tự tạo ra những nước đi của chính nó và không cần đến con người can thiệp vào quá trình học, nó đánh bại phiên bản cao nhất của bot chơi cờ vua mà hầu như các bạn chơi đều biết – StockFish 8 với tỉ số 28 – 0 (72 trận khác hòa).
Tại sao những AI chơi game như vậy lại được liệt kê trong lược sử của DL, chẳng phải nó chỉ đơn giản dùng MCTS thôi ư? Đối với Dota 2, đây là trò chơi online, muốn một con bot đánh được thì nó cần phải nhìn vào screen với map, do đó CV đóng một vai trò rất quan trọng. Đối với AlphaGo/Zero cũng tương tự, không chỉ mã hóa bàn cờ bằng CV, sự kết hợp với Guided MCTS giúp nó khai phá dữ liệu trò chơi sâu hơn, các kỹ thuật và khả năng lượng giá của nó được mã hóa bởi CNN, nước đi được tạo ra bởi Generative Adversarial Network (GAN) để định hướng cho MCTS.
Sẽ thiếu sót nếu như không đề cập đến sự kiện OpenAI ra mắt ChatGPT, một chatbot AI có khả năng tương tác ở dạng đàm thoại và đưa ra những phản hồi bằng ngôn ngữ tự nhiên. Công cụ này đã cán mốc 100 triệu người dùng chỉ 2 tháng sau khi ra mắt, trở thành ứng dụng tiêu dùng phát triển nhanh nhất trong lịch sử.
Màn ra mắt bùng nổ của ChatGPT là cú huých dẫn đến hình thành một cuộc đua nghiên cứu, phát triển và ứng dụng AI trên phạm vi toàn cầu, với sự tham gia của hàng loạt ông lớn công nghệ như Microsoft, Google, Alibaba, Baidu…
VI. Kết bài
1. Tương lai
Trước sự phát triển vượt bậc đó, DL hứa hẹn sẽ mang lại những thành quả bất ngờ và những bước tiến của nó sẽ ảnh hưởng sâu rộng hơn đến cuộc sống của mỗi người trong xã hội hiện đại. DL mang đến một thời đại mới với cuộc cách mạng cũng nó cũng như đặt ra các thách thức cho mỗi người để không bị thay thế.
Nhiều người sẽ cho rằng, trong tương lai gần, các AI sẽ có thể mô phỏng thật giống con người. Thực tế cho thấy đó không phải là điều không thể. Nhưng có lẽ ngày đó sẽ còn xa lắm, nếu như chúng ta phát triển DL theo cách như hiện nay?
Người đứng đầu cơ quan phát triển AI của Facebook, LeCun cho rằng DL đang dần trở thành một thứ như Giả kim thuật, với việc các model là một blackbox, chúng ta không thể biết chúng đã học được những gì từ dataset, những thứ chúng học có đúng không, hay thậm chí những điều chúng ta biết về chúng có chính xác không?
Nguyên nhân cho việc này là những nghiên cứu phát triển theo cấp số mũ, không có định hình được cụ thể những nguyên lý khác ngoài việc tạo ra model hay dataset (e.g. việc tại sao một số model converge được trong khi một số thì không vẫn chưa có lời giải, việc giải nghĩa các weight của ANN vẫn còn là một bí ẩn, …).
2. Những người mới
Những nhà nghiên cứu đã rất cố gắng trong việc tạo ra model bằng những nghiên cứu trước đó, các phân tích cụ thể cho vài trò của từng thành phần trong ANN và sử dụng các dataset phù hợp để đưa model đạt accuracy tốt nhất. Đó là cả một quá trình để có thể tạo ra được một model chấp nhận được, không phải dễ dàng để có được Ph.D hay Postdoc trong ngành DL.
Việc học cũng vậy, những người mới tham gia vào có thể theo học các course được các Professors đầu ngành hoặc các kỹ sư chuyên ngành tại các tập đoàn lớn. Để nắm rõ được DL, bạn cần phải có một nền tảng toán học tương đối và tư duy lập trình căn bản, nhất là niềm đam mê với ngành, nếu không, những sự khó khăn sẽ khiến cho bạn từ bỏ sớm.
ThS. Bùi Hùng Vương - Sưu tầm và biên soạn lại.
Thông báo: Giải bóng đá sinh viên Khoa Công nghệ thông tin năm 2024 - 17/04/2024
Thông báo cuộc thi "Kỹ thuật phần mềm Khoa CNTT năm 2024" - 12/04/2024
Một doanh nghiệp nhỏ có thể là lựa chọn tốt nhất cho một bước tiến lớn trong sự nghiệp - 17/03/2024
Gemini Chat - 17/03/2024
Toán cho học máy - 29/02/2024
Báo cáo Khóa luận tốt nghiệp của sinh viên khóa 2020 Ngành CNTT và KTPM- 16/01/2024
Báo cáo Thực tập tốt nghiệp của sinh viên khóa 2019 - 2020 Ngành CNTT và KTPM- 10/01/2024
TIỀN MÃ HÓA CRYPTOCURRENCY- 17/12/2023
GPU dưới dạng dịch vụ: Những điều chuyên gia CNTT cần biết- 01/12/2023
Khoa CNTT Trường ĐH Nguyễn Tất Thành tổ chức chọn chuyên ngành cho Sinh viên Khóa 2022- 27/10/2023


Kế hoạch Khóa Luận Tốt nghiệp HK2 - 2023
22/01/2024


22/11/2022
Hệ thống MegaSchool và MegaTest thông báo tuyển dụng Thực tập sinh
13/07/2022
TMA Solutions - Cơ hội việc làm dành cho sinh viên Khoa CNTT
04/07/2022
10/06/2022
T UYỂN DỤNG NHÂN VIÊN HÀNH CHÍNH IT– TEXGAMEX-VN
16/05/2022
Thông tin tuyển dụng công ty PORTLOGICS - PLC
15/04/2022
Ngân hàng Á Châu (ACB) tuyển Chuyên viên Dịch vụ IT – Hồ Chí Minh





