


Dự đoán không phá hủy những đặc trưng lý hóa
Ngày đăng: 12/12/2024
Có nhiều phương pháp để có thể đo lường những đặc trưng lý hóa của sốt kimchi với độ chính xác cao và đáng tin cậy. Tuy nhiên, chúng đòi hỏi nhiều giai đoạn chuẩn bị cần thiết, phá hủy (destructive) những đặc trưng lý hóa của sốt kimchi và tiêu tốn thời gian.
I. Giới thiệu về dự đoán không phá hủy những đặc trưng lý hóa của sốt kimchi
1.1. Tổng quan về sốt kimchi
Kimchi là một loại thực phẩm nổi tiếng của Hàn Quốc. Mỗi loại kimchi đều được sản xuất bằng cách trộn lẫn nhiều loại sốt và đa dạng rau củ quả, sau đó được lên men một cách tự nhiên trong một khoảng thời gian dài. Trong đó, sốt kimchi chiếm 20% của sản phẩm kimchi. Do vậy, chất lượng của sốt kimchi có thể ảnh hưởng đến những đặc trưng lý hóa và sự lên men của kimchi, từ đó ảnh hưởng đến cả thành phẩm cuối cùng. Một loại sốt kimchi chất lượng bị chi phối bởi nhiều tác nhân bao gồm độ mặn (salinity), độ hòa tan chất rắn trong chất lỏng (°Brix), độ ẩm (moisture content) và màu sắc (color).

Hình 1: Minh họa cho sốt kimchi
1.2. Dự đoán không phá hủy
Có nhiều phương pháp để có thể đo lường những đặc trưng lý hóa của sốt kimchi với độ chính xác cao và đáng tin cậy. Tuy nhiên, chúng đòi hỏi nhiều giai đoạn chuẩn bị cần thiết, phá hủy (destructive) những đặc trưng lý hóa của sốt kimchi và tiêu tốn thời gian.
Vì vậy, những cách tiếp cận không phá hủy (nondestructive), phân tích dữ liệu một cách tổng quát và không cần biết trước các đặc điểm cụ thể của nó (non-targeted fingerprinting) là phù hợp hơn trong việc kiểm soát chất lượng sản phẩm bởi chúng tạo ra kết quả nhanh và có hiệu quả chi phí. Bên cạnh đó, việc dự đoán theo thời gian thực (real-time) nhanh chóng dựa trên tầm nhìn (vision) có sức hấp dẫn, lôi cuốn hơn nhiều.
Tóm lại, đây là phương pháp giúp con người thông qua những gì quan sát được hay từ hình ảnh của sốt kimchi mà đưa ra dự đoán. Mục đích chính là tránh sự phức tạp về phân tích lẫn tính toán nhưng đem lại hiệu quả cao.
1.3. Học sâu (Deep learning)
Nền tảng xây dựng nên phương pháp dự đoán không phá hủy những đặc trưng lý hóa chính là học sâu.
Học sâu là một trong những lĩnh vực đang phát triển vô cùng mạnh mẽ trong những năm gần đây. Đây là lĩnh vực có tiềm năng khai thác to lớn và đầy triển vọng. Sơ lược về học sâu thì đây là một nhánh con của học máy (machine learning) thuộc ngành Trí tuệ nhân tạo (Artificial Intelligence). Không giống với học máy phải chỉ ra rõ ràng phương pháp tính toán để tìm ra kết quả, tự bản thân deep learning nhờ có quá trình backforward và lặp đi lặp lại nhiều lần mà đã tìm ra được những trọng số phù hợp nhất. Tuy tiềm năng là thế nhưng nhược điểm của học sâu đó chính là yêu cầu lượng dữ liệu nhiều. Càng nhiều dữ liệu thì mô hình huấn luyện càng chính xác và có độ tin cậy cao.
Phụ thuộc vào quy mô doanh nghiệp, có thể lựa chọn các phương pháp khác nhau của học sâu. Song, trong đó có thể kể đến hai phương pháp chính là ANN (sử dụng cho doanh nghiệp nhỏ nơi mà thu thập dữ liệu về hình ảnh là một thử thách) và CNN (được chia làm hai loại S-CNN và D-CNN, được sử dụng cho môi trường nơi mà hình ảnh là khả dụng).
1.4. Ứng dụng
Không chỉ sốt kimchi, phương pháp này có thể áp dụng cho ngành Công nghệ thực phẩm nhằm hỗ trợ kiểm soát tốt hơn chất lượng sản phẩm. Ngoài ra còn có thể lợi dụng phương pháp để sử dụng cho các ngành khác như Nông nghiệp, phát hiện các đặc trưng mà nơi đó là vùng có sâu bệnh hay cây có sâu bệnh thông qua hình ảnh,...
II. Phân tích phương pháp
Trước khi đưa vào các phương pháp của học sâu để đưa ra dự đoán, dữ liệu về sốt kimchi cần được tiền xử lí và chuẩn hóa. Đối với dữ liệu sốt kimchi đưa vào ANNs, có thể sử dụng các phương pháp tiền xử lí và chuẩn hóa cho dữ liệu có cấu trúc (csv, excel). Đối với dữ liệu sốt kimchi đưa vào CNNs, dữ liệu cần được đưa về 73x73 pixels và sử dụng các phương pháp tiền xử lí và chuẩn hóa cho dữ liệu không cấu trúc (hình ảnh).
Với mỗi phương pháp bên dưới sẽ tạo ra ba mô hình mà kết quả thu được sẽ là dự đoán về ba nhân tố tạo nên chất lượng kimchi: độ mặn, độ hòa tan chất rắn trong chất lỏng và độ ẩm.
2.1. ANN – Artificial Neural Network
ANN hay Mạng thần kinh nhân tạo là một trong những phương pháp cơ bản và quan trọng của học sâu. Mạng được tổ chức mô phỏng theo mạng lưới thần kinh của con người. ANN bao gồm ba lớp (layer) chính: Input – Hidden – Output. Với lớp Input là lớp làm việc trực tiếp với dữ liệu, lớp Hidden (lớp ẩn) sẽ học từ dữ liệu ở lớp Input và lớp Output sẽ đưa ra kết quả dự đoán.
Thiết kế mô hình ANNs:
+ Lớp Input: Gồm 3 nodes lần lượt là 3 giá trị L* (brightness), a* (redness) và b* (yellowness) của mỗi mẫu (sample) kimchi.
+ Lớp Hidden: Tối đa 5 lớp với mỗi lớp có số node là lũy thừa cơ số 2 bắt đầu từ 23 và tăng dần từ phải qua trái. Ví dụ nếu sử dụng 4 lớp thì lần lượt số node có trong 4 lớp này là 64-32-16-8. Các hàm kích hoạt có thể lựa chọn bao gồm ReLU, ELU, Tanh và Leaky ReLU.
+ Lớp Output: Gồm 1 node trả về kết quả thu được về độ mặn hoặc độ hòa tan chất rắn trong chất lỏng hoặc độ ẩm.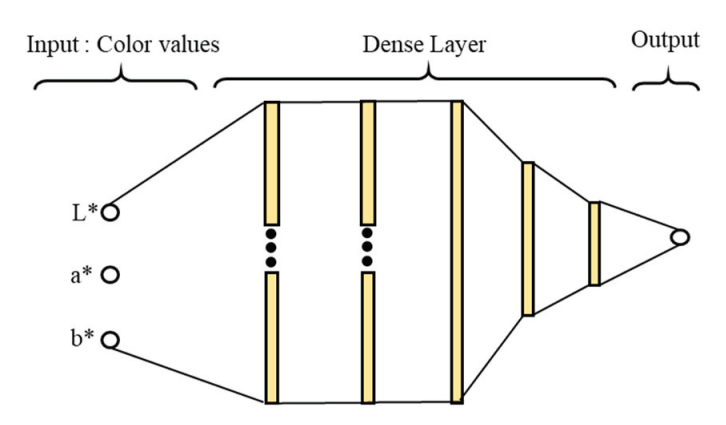
Hình 2: Artificial Neural Network
2.2. CNN – Convolutional Neural Network
CNN hay Mạng tích chập là một mạng được sử dụng rộng rãi trong các nhiệm vụ liên quan đến hình ảnh. Vì vậy, đầu vào của CNN sẽ là hình ảnh, sau đó thông qua một cửa sổ trượt (Filter hay Kernel) và Pooling, mạng rút trích được những đặc trưng của hình ảnh được đưa vào.
Hàm tích chập: (f * g)(t) = -∞f.gt-τdτ
Sử dụng ReLU nhằm tăng tính phi tuyến (nonlinear) của hình ảnh để mô hình có thể học tốt hơn.
CNN như đã được đề cập trước đó được chia làm hai loại Shallow-CNN (CNN nông) và Deep-CNN (CNN sâu). S-CNN có cấu trúc không quá phức tạp và được sử dụng cho các bài toán đơn giản. D-CNN thì có cấu trúc phức tạp hơn S-CNN, dùng để giải quyết các bài toán cần sự thách thức bởi có thể phân tích toàn diện, cải thiện hiệu suất và chính xác hơn.
Các cấu trúc S-CNN bao gồm: CMCM, MCCC, CCCM và CCCC. Các cấu trúc D-CNN gồm các mạng DenseNet, Resnet18, Resnet50.
Để đánh giá hiệu suất của các mô hình CNN, có thể sử dụng MSE (Mean Squared Error), MAPE (Mean Absolute Percentage Error), RMSE (Root Mean Square Error) và R2.
MSE=1nn=1n(yi-yi)2
MAPE(%)=1nn=1nyi-yiyi.100
RMSE=(1nn=1n(yi-yi)2)0.5
R2=1-i=1n(yi-yi)2i=1n(yi-yi)2
Hình 3: Convolutional Neural Network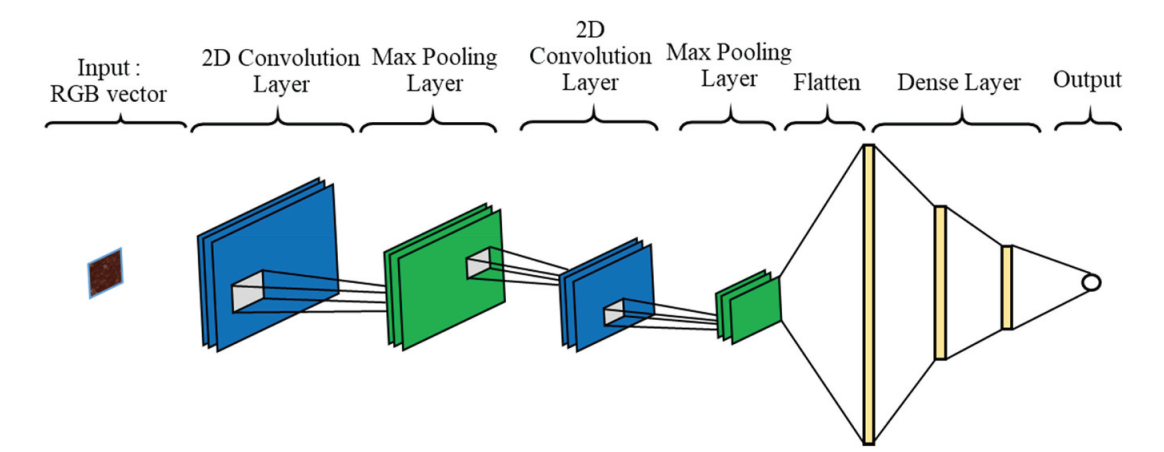
Hình 4: S-CNN architectures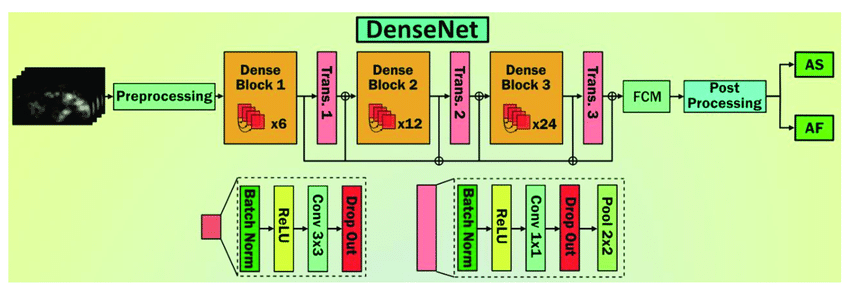
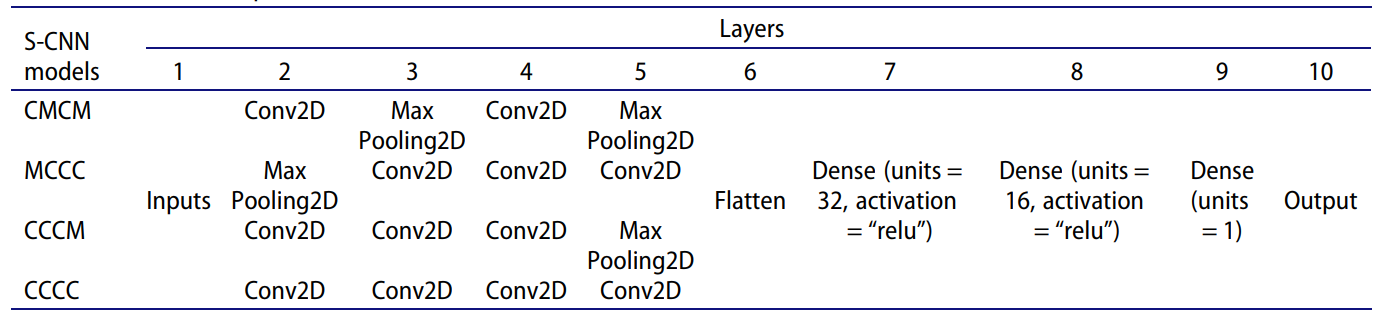
Hình 5: DenseNet
Hình 6: ResNet18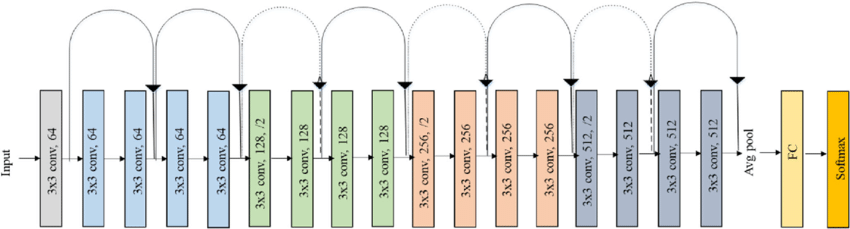
Hình 7: ResNet50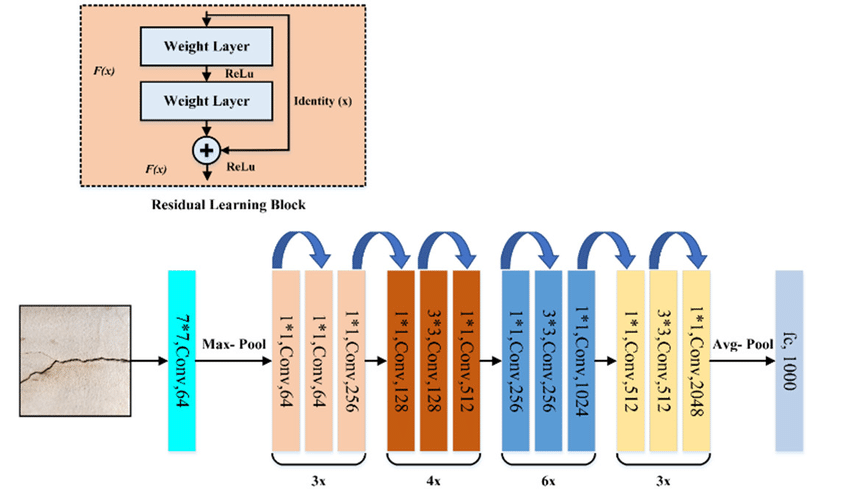
III. Tài liệu tham khảo
[1] Hae-Il Yang, Seong Youl Lee, Mi-Ai Lee, Jong-Bang Eun. “Nondestructive prediction of physicochemical properties of kimchi sauce with artificial and convolutional neural networks”. Article in International Journal of Food Properties October 2023.
BM TTNT Khoa CNTT
Sinh viên Công Nghệ Thông Tin tiếp cận AI trong học tập, và phát triển sự nghiệp bản thân - 11/12/2024
Bảng các đội tham dự và Thời gian thi đấu Giải bóng đá SV Khoa CNTT năm 2022 - 25/06/2022
Điều kiện đăng ký khóa luận 2017 - Thực tập tốt nghiệp 2018 - 21/04/2021
Danh sách sinh viên Khóa 19 phân chuyên ngành - 14/04/2021
Đăng ký học lại - 25/01/2021
Khảo sát ý kiến người học- 21/01/2021
HƯỚNG DẪN ĐÓNG HỌC PHÍ- 23/12/2020
Bảo vệ khóa luận tốt nghiệp Sinh viên niên khóa 2015-2019.- 09/08/2020




10/09/2024
THÔNG BÁO: Thời gian và địa điểm + DS hội đồng báo cáo Thực tập tốt nghiệp HK3 NH2023 - 202413/08/2024
Kế hoạch Khóa Luận Tốt nghiệp Ngành Công nghệ Thông tin, Ngành Kỹ thuật phần mềm và Ngành Mạng máy tính và truyền thông dữ liệu - HK1 Năm học 2024 - 202513/08/2024
Kế hoạch Thực tập tốt nghiệp Ngành Công nghệ thông tin, Ngành kỹ thuật phần mềm và Ngành Mạng máy tính và Truyền thông dữ liệu - HK1 Năm học 2024 - 202522/11/2022
Hệ thống MegaSchool và MegaTest thông báo tuyển dụng Thực tập sinh
13/07/2022
TMA Solutions - Cơ hội việc làm dành cho sinh viên Khoa CNTT
04/07/2022
10/06/2022
T UYỂN DỤNG NHÂN VIÊN HÀNH CHÍNH IT– TEXGAMEX-VN
16/05/2022
Thông tin tuyển dụng công ty PORTLOGICS - PLC
15/04/2022
Ngân hàng Á Châu (ACB) tuyển Chuyên viên Dịch vụ IT – Hồ Chí Minh





