


Deepfakes & Cheapfakes
Ngày đăng: 27/07/2023
Deepfakes và Cheapfakes đều liên quan đến việc giả mạo thông tin, nhưng có một số khác biệt trong cách chúng được tạo ra và mức độ khó khăn trong việc phát hiện.
Định nghĩa: Deepfakes là thuật ngữ được sử dụng để chỉ các sản phẩm được tạo ra để giả mạo thông tin, chẳng hạn như thay đổi khuôn mặt của người này vào hình ảnh của người khác hoặc biến đổi giọng nói, bằng cách sử dụng các công cụ trí tuệ nhân tạo như machine learning và deep learning.
Điều đáng ngạc nhiên là Deepfakes có thể ghép khuôn mặt của một người vào hình ảnh hoặc video của người khác một cách tự nhiên và khá chân thực. Tuy nhiên, điều đáng lo ngại là sự tiềm ẩn của việc sử dụng Deepfakes để gây hại và lừa đảo. Ví dụ, bằng cách gắn khuôn mặt của người nổi tiếng vào các hoạt động phi pháp, những người tạo ra Deepfakes có thể tạo ra những thông tin sai lệch và gây ảnh hưởng tiêu cực đến danh dự và uy tín của những người đó. Hơn nữa, Deepfakes cũng có thể được sử dụng để đánh lừa các hệ thống nhận dạng khuôn mặt. Bằng cách ghép khuôn mặt của một người lạ vào video, Deepfakes có thể làm cho hệ thống nhận dạng khuôn mặt nhầm lẫn và chấp nhận người giả là người thật. Một ví dụ minh họa: Kỹ thuật video deepfake có thể đưa chữ vào miệng người nổi tiếng, chính trị gia và cả công chúng.
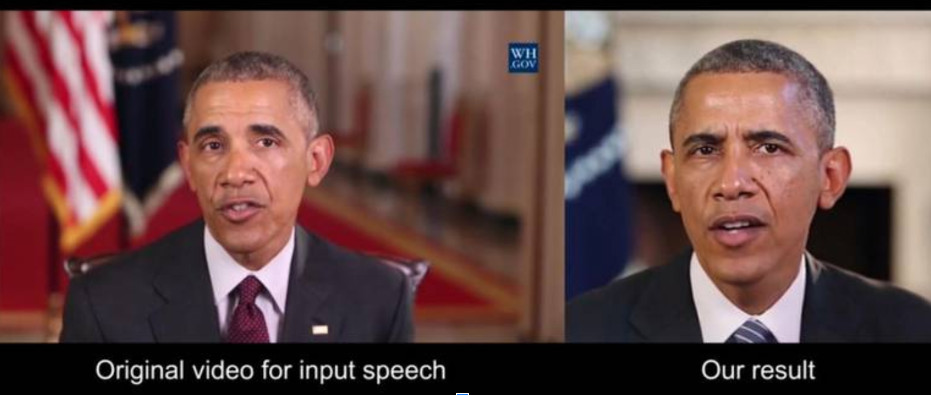
“Ảnh chụp màn hình video Tổng hợp Obama: Học hát nhép từ Audio. Đầu tiên, mạng nơ-ron chuyển đổi âm thanh từ tệp âm thanh thành các hình dạng miệng cơ bản. Sau đó, hệ thống sẽ ghép và trộn các hình dạng miệng đó vào một video mục tiêu hiện có và điều chỉnh thời gian để tạo một video chân thực, được đồng bộ hóa môi mới.”
Chúng ta đã nói về Deepfakes và những nguy cơ của nó trong thời đại công nghệ hiện nay, nhưng có một khái niệm, giả mạo thông tin nguy hiểm không kém vừa mới định hình trong một vài năm gần đây, đó là Cheapfakes.
Định nghĩa: Cheapfakes là một loại giả mạo thông tin giá rẻ và không yêu cầu kiến thức chuyên ngành cao để tạo ra. Cheapfakes bao gồm các hành động đơn giản như cắt ghép ảnh, chỉnh sửa nội dung văn bản hoặc thay đổi câu chủ đề của một hình ảnh trong bài viết này vào câu chủ đề của hình ảnh trong bài viết khác. Cheapfakes tạo ra hiểu nhầm trong việc tiếp nhận thông tin bằng cách thay đổi ngữ cảnh hoặc đánh lừa người đọc. Nếu như Deepfakes yêu cầu người ta phải có kiến thức về AI, thì Cheapfakes chỉ cần một vài thao tác cơ bản như cắt ghép ảnh, chỉnh sửa nội dung văn bản, hay đơn giản thay đổi câu chủ đề của hình trong bài viết này này vào câu chủ đề của hình trong bài viết khác.
Cheapfakes được giới thiệu đến cộng đồng lần đầu tiên như một bài toán thực tế kèm theo dữ liệu để cộng đồng AI có thể giải quyết bởi tác giả Shivangi và cộng sự. Nhóm của tác giả Shivangi đề ra bài toán Cheapfakes nhỏ bao gồm một hình ảnh và hai câu chủ đề, đặt ra việc hình ảnh có thể bị sử dụng lại giữa hai câu chủ đề cho mục đích khác hay không, nhóm tác giả định nghĩa trường hợp sử dụng này là Out-of-context (tạm dịch khác ngữ cảnh) và đồng thời khuyến khích cộng đồng giải quyết bài toán nhận biết Cheapfakes.

Ví dụ về bài toán của Nhóm tác giả Shivangi, ở hình 2 bên trái, câu chủ đề cho hình ảnh bao gồm C1 và C2. C1 mô tả rằng “Tổng thống Obama đang ở 1 Lab nào đó ở Wuhan vào năm 2015 trong dự án nghiên cứu về dơi”. C2 mô tả rằng “Tổng thống Omaba đang ở NIH lab trong 1 dự án nghiên cứ về vaccine Ebola”. Rõ ràng với góc người đọc vào năm 2015, việc Tổng thống Obama xuất hiện tại Wuhan, China trong một dự án về dơi là một điều khó có thể xảy ra, do nhiều yếu tố như mối quan hệ ngoại giao của Mỹ và Trung Quốc, và một dự án về dơi thì khó có thể làm cho tổng thống Obama giành thời gian cho nó được. Nhưng nếu bạn đọc thông tin này vào những năm đại dịch Covid-19 diễn ra, thì bạn có thể bị ngộ nhận rằng tổng thống Obama có dính líu để sự bùng phát của đại dịch. Rõ ràng rằng C1 là một câu chủ đề được chỉnh sửa sai sự thật, và hướng người đọc vào thông tin sai lệch.
Với bộ dữ liệu được công bố của nhóm tác giả Shivangi, đã có nhiều bài báo được công bố, thậm chí có những cuộc thi để phát hiện Cheapfakes như “Grand Challenge on Detecting Cheapfakes” tại MMSys 2021, ACM Multimedia 2022 và gần đây nhất IEEE ICME 2023, thu hút được nhiều nhà nghiên cứu trong cộng đồng cùng tham gia đóng góp ý tưởng trong việc phát hiện Cheapfakes.
Về các ý tưởng để phát hiện Cheapfakes, bạn đọc có thể tham khảo các công trình ở mục công trình liên quan. Nhưng về ý tưởng để phát hiện Cheapfakes của các nhà nghiên cứu chủ yếu xoay quanh việc chuyển đổi hình ảnh và hai câu chủ đề C1, C2 về dạng Vector (một dãy số) để máy tính có thể hiểu được, từ dạng Vector này có thể tính toán sự khác biệt, giống nhau giữa hai câu chủ đề và hình ảnh bằng công cụ toán học như tính khoảng cách Euclide hay Cosine, … Từ đó các nhà nghiên cứu có thể chỉ cho máy tính phát hiện đâu là Cheapfakes bằng cách so sánh sự giống và khác nhau của hình ảnh và câu chủ đề, chúng sẽ là Cheapfakes nếu chúng quá khác biệt.
Gần đây do sự phát triển của công nghệ, cũng như việc thúc đẩy, gia tăng các công trình nghiên cứu trong lĩnh vực AI, các thuật toán được nâng cấp một cách nhanh chóng, các công ty đầu ngành trong lĩnh vực như Meta, Google, OpenAI, có xu hướng công bố công khai các bài báo khoa học, các mô hình mà phải tốn hàng tháng của họ huấn luyện được để cộng đồng có thể sử dụng miễn phí. Vô tình chung điều này làm cho việc tiếp cận đến AI và sản phẩm của nó ngày càng dễ dàng. Những mô hình tự tạo hình ảnh, hay Chatbot có thể tự tạo nội dung văn bản được sử dụng miễn phí như ChatGPT, DALL-E của OpenAI làm cho việc tạo ra Cheapfakes vô cùng dễ dàng. Tuy nhiên để xác minh thông tin là giả, chúng ta cần rất nhiều bước như xác minh nguồn ảnh, từ nguồn ảnh xác minh các câu chủ đề liên quan, nguồn ảnh có đáng tin cậy, được đăng trên trang báo uy tín hay không… Điều này làm cho Cheapfakes vô cùng nguy hiểm vì lý do dễ tạo, khó xác minh, thiệt hại lớn. Không những thế những năm gần đây với sự phổ biến của Deepfakes và khả năng dễ tiếp cận của nó đối với cộng đồng, các công cụ tạp nên Deepfakes dần trở thành công cụ để tạo nên Cheapfakes.
GV L. T. M. Thanh_Bộ môn KHCB
Giao lưu bóng đá Chào mừng 42 năm ngày Nhà giáo Việt Nam ngày 17/11/2024 - 17/11/2024
IoV (Internet of Vehicle) - Kỷ nguyên mới của ngành giao thông - 07/11/2024
Tư vấn Chuyên ngành cho sinh viên Khóa 2023, Khoa Công Nghệ thông tin – Đại Học Nguyễn Tất Thành, ngày 31/10/2024 - 01/11/2024
Công nghệ AI: đầy triển vọng và thách thức năm 2024 - 16/08/2024
Ứng dụng chuyển đổi số trong lĩnh vực thương mại điện tử - 17/07/2024
Sự kỳ diệu của Toán học trong thiên nhiên- 01/07/2024
Chuyển đổi số trong lĩnh vực tài chính- 15/05/2024
8 bước để trở thành nhà khoa học dữ liệu- 27/04/2024
Ứng Dụng Chuyển Đổi Số Trong Lĩnh Vực Chăm Sóc Sức Khỏe: Xu Hướng Phát Triển- 20/03/2024
Công nghệ Blockchain: Giải pháp bảo vệ chống Deepfake và tăng cường an toàn dữ liệu trong Thương mại điện tử- 17/03/2024




13/08/2024
Kế hoạch Thực tập tốt nghiệp Ngành Công nghệ thông tin, Ngành kỹ thuật phần mềm và Ngành Mạng máy tính và Truyền thông dữ liệu - HK1 Năm học 2024 - 202531/05/2024
Kế hoạch thực tập tốt nghiệp Ngành CNTT - HK3 Năm học 2023 - 202416/05/2024
THÔNG BÁO: THỜI GIAN VÀ ĐỊA ĐIỂM + DANH SÁCH HỘI ĐỒNG BÁO CÁO KHOÁ LUẬN TỐT NGHIỆP22/11/2022
Hệ thống MegaSchool và MegaTest thông báo tuyển dụng Thực tập sinh
13/07/2022
TMA Solutions - Cơ hội việc làm dành cho sinh viên Khoa CNTT
04/07/2022
10/06/2022
T UYỂN DỤNG NHÂN VIÊN HÀNH CHÍNH IT– TEXGAMEX-VN
16/05/2022
Thông tin tuyển dụng công ty PORTLOGICS - PLC
15/04/2022
Ngân hàng Á Châu (ACB) tuyển Chuyên viên Dịch vụ IT – Hồ Chí Minh





