fit@ntt.edu.vn
fit@ntt.edu.vn 028 71080889
028 71080889
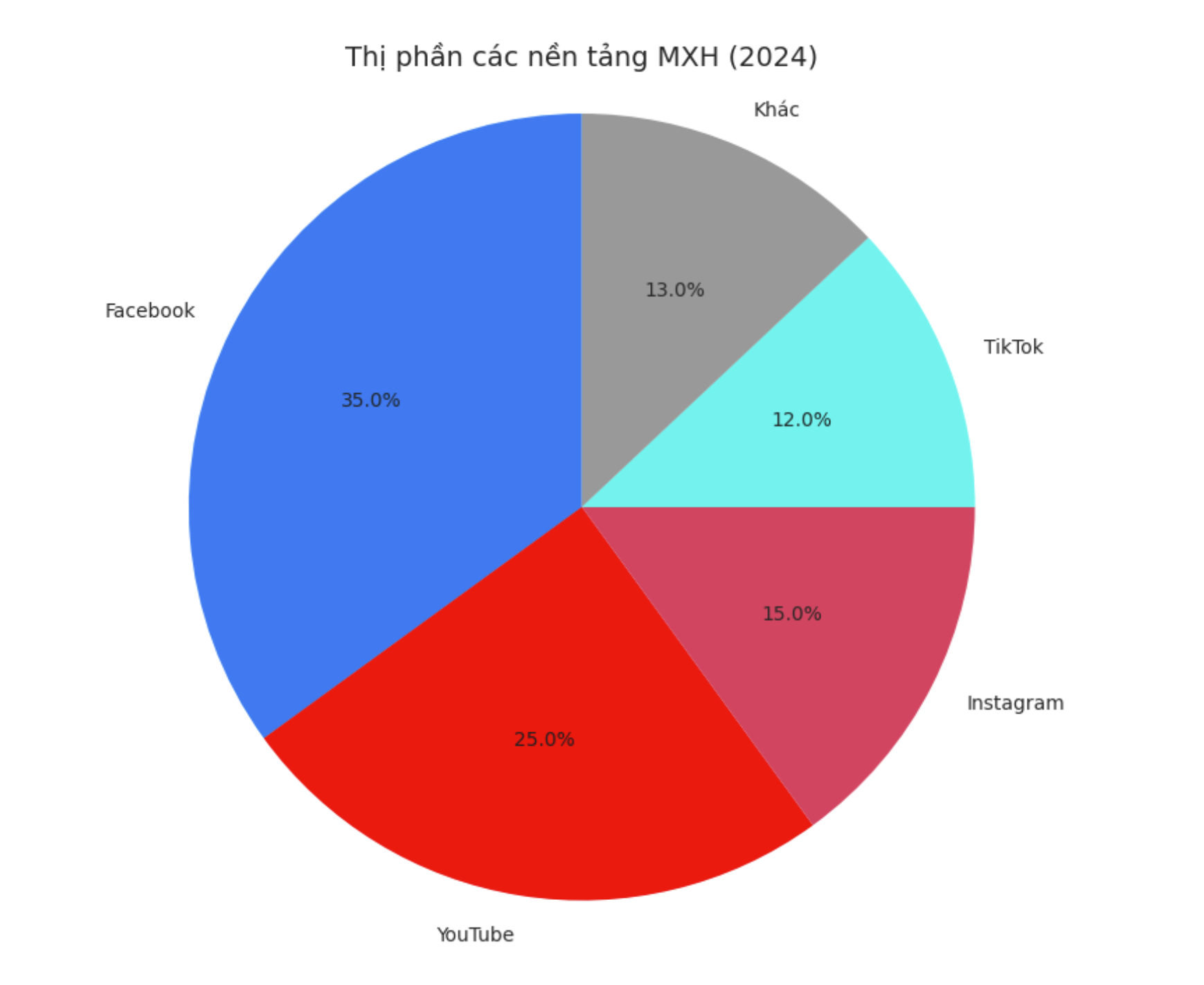
Trong kỷ nguyên số hóa mạnh mẽ hiện nay, mạng xã hội đã trở thành một phần không thể thiếu trong đời sống hàng ngày của hàng tỷ người trên toàn thế giới. Không chỉ là nơi kết nối và chia sẻ thông tin, mạng xã hội còn phản ánh hành vi, suy nghĩ, cảm xúc và xu hướng của cộng đồng một cách sống động và liên tục. Những dữ liệu được tạo ra từ các nền tảng như Facebook, Twitter, Instagram, TikTok hay YouTube mang giá trị to lớn nếu được khai thác một cách khoa học và hiệu quả.
Khai thác dữ liệu mạng xã hội (Social Media Data Mining) là quá trình sử dụng các kỹ thuật và công cụ để thu thập, xử lý, phân tích và trích xuất thông tin hữu ích từ nguồn dữ liệu khổng lồ này. Ứng dụng của khai thác dữ liệu mạng xã hội trải rộng trong nhiều lĩnh vực như marketing, y tế, giáo dục, chính trị, và cả quản trị rủi ro truyền thông. Tuy nhiên, đi kèm với cơ hội là những thách thức về bảo mật, quyền riêng tư và khả năng xử lý dữ liệu phức tạp, đa dạng. Vì vậy, việc nắm vững các phương pháp thu thập, làm sạch và tổng hợp dữ liệu mạng xã hội là yếu tố then chốt giúp khai thác hiệu quả giá trị tiềm ẩn trong không gian số.

Khai thác dữ liệu mạng xã hội
Trong thời đại công nghệ số bùng nổ, mạng xã hội không chỉ là công cụ giao tiếp mà còn là kho dữ liệu khổng lồ phản ánh hành vi, xu hướng và tâm lý của người dùng. Khai thác dữ liệu mạng xã hội (Social Media Data Mining) là quá trình thu thập, xử lý, phân tích và diễn giải dữ liệu được tạo ra từ các nền tảng mạng xã hội như Facebook, Twitter, Instagram, TikTok, YouTube… để rút ra thông tin giá trị phục vụ các mục tiêu cụ thể như tiếp thị, phân tích hành vi người tiêu dùng, dự đoán xu hướng, hỗ trợ ra quyết định hoặc nghiên cứu học thuật.
Khai thác dữ liệu mạng xã hội đóng vai trò quan trọng trong nhiều lĩnh vực, từ kinh doanh, giáo dục đến chính trị. Ví dụ, các công ty có thể hiểu được nhu cầu khách hàng thông qua phân tích bình luận, lượt thích và chia sẻ, từ đó điều chỉnh sản phẩm hoặc chiến lược marketing. Trong lĩnh vực y tế, các tổ chức có thể giám sát sự lan truyền của thông tin về dịch bệnh hay đánh giá phản ứng của cộng đồng về một loại vaccine.
Tuy nhiên, việc khai thác dữ liệu mạng xã hội cũng đối mặt với nhiều thách thức như quyền riêng tư, độ tin cậy của dữ liệu và khả năng xử lý khối lượng lớn dữ liệu phi cấu trúc. Chính vì vậy, việc áp dụng các phương pháp hiện đại trong thu thập, xử lý và phân tích dữ liệu trở nên cấp thiết để tối ưu hóa giá trị thông tin thu được.
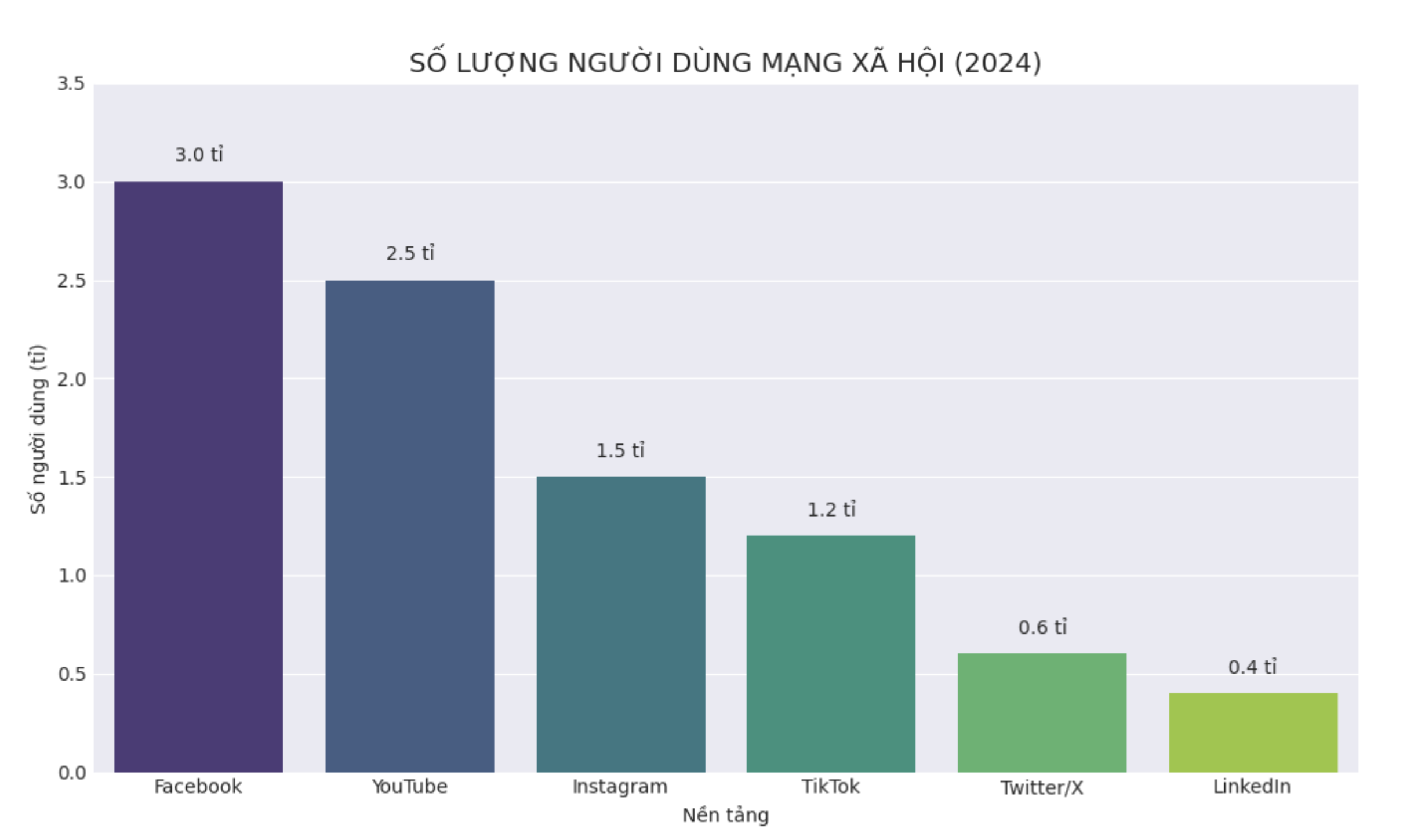
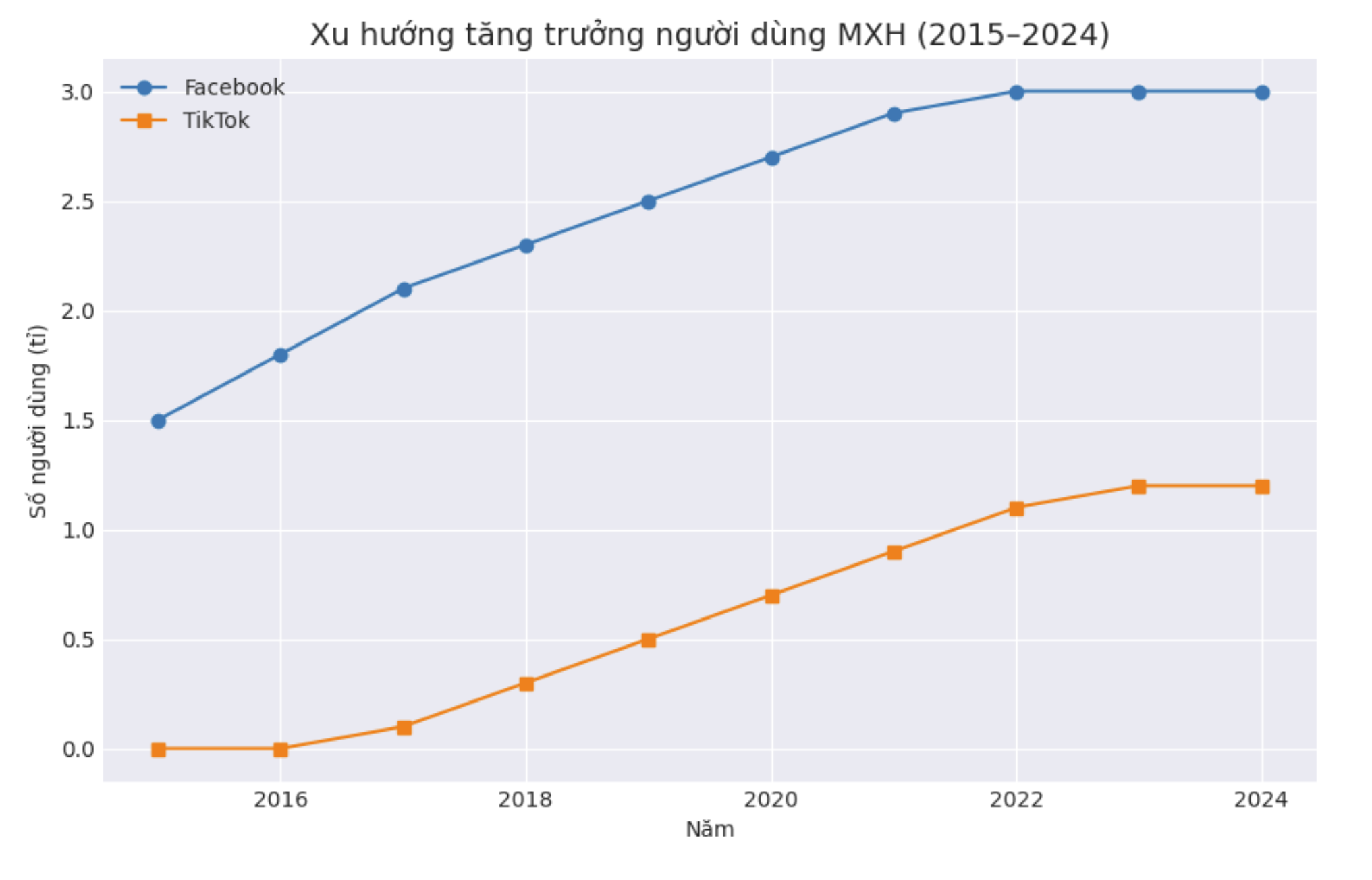
Dữ liệu mạng xã hội phổ biến
Dữ liệu mạng xã hội được tạo ra mỗi giây dưới nhiều dạng khác nhau và có những đặc điểm nổi bật như đa dạng, khối lượng lớn, phi cấu trúc và mang tính thời gian thực. Có thể phân loại dữ liệu mạng xã hội thành một số nhóm chính như sau:
- Dữ liệu văn bản: Đây là loại dữ liệu phổ biến nhất, bao gồm các bài đăng (post), bình luận (comment), tin nhắn, mô tả trạng thái, hashtag và các đoạn hội thoại. Dữ liệu văn bản thường mang tính chủ quan và phản ánh cảm xúc, ý kiến của người dùng.
- Dữ liệu hình ảnh và video: Người dùng thường xuyên đăng tải hình ảnh, video lên các nền tảng như Instagram, TikTok, Facebook hoặc YouTube. Phân tích dữ liệu hình ảnh và video yêu cầu kỹ thuật thị giác máy tính (Computer Vision) để nhận dạng nội dung, khuôn mặt, vật thể hay bối cảnh.
- Dữ liệu tương tác: Gồm các lượt thích (like), chia sẻ (share), gắn thẻ (tag), nhấn theo dõi (follow) hay các mối quan hệ bạn bè. Dữ liệu này giúp xây dựng mạng lưới xã hội và phân tích mức độ ảnh hưởng của người dùng.
- Dữ liệu địa điểm (location-based data): Nhiều bài đăng có kèm theo thông tin định vị, giúp xác định vị trí địa lý của người dùng, hỗ trợ phân tích hành vi theo vùng, khu vực, quốc gia.
- Dữ liệu siêu dữ liệu (metadata): Bao gồm thời gian đăng bài, thiết bị sử dụng, nguồn truy cập,… giúp đánh giá hành vi sử dụng mạng xã hội trong không gian và thời gian.
Dữ liệu mạng xã hội không chỉ có khối lượng lớn mà còn thay đổi liên tục, đòi hỏi các hệ thống phải có khả năng xử lý thời gian thực và thích ứng cao. Tính phi cấu trúc và đa phương tiện của dữ liệu cũng làm gia tăng độ phức tạp trong việc khai thác và phân tích.
Phương pháp thu thập khai thác dữ liệu
Việc thu thập dữ liệu mạng xã hội cần tuân thủ các nguyên tắc đạo đức và quy định pháp luật về quyền riêng tư. Dưới đây là một số phương pháp phổ biến:
- Sử dụng API công khai
Nhiều nền tảng mạng xã hội cung cấp các API (Application Programming Interface) để nhà phát triển truy cập dữ liệu, như:
- Facebook Graph API
- Twitter API
- YouTube Data API
- Instagram Basic Display API
API cho phép truy xuất dữ liệu người dùng công khai, bao gồm bài đăng, bình luận, lượt tương tác và thông tin hồ sơ. Tuy nhiên, việc sử dụng API thường bị giới hạn số lượng truy vấn hoặc yêu cầu xác thực người dùng.
- Web Scraping
Kỹ thuật cào dữ liệu (web scraping) được sử dụng khi API không cung cấp đủ thông tin cần thiết. Bằng cách sử dụng các công cụ như BeautifulSoup, Selenium, Scrapy,… dữ liệu có thể được thu thập từ giao diện người dùng của các trang mạng xã hội.
Web scraping cần thận trọng vì có thể vi phạm điều khoản dịch vụ hoặc bị các nền tảng chặn địa chỉ IP. Hơn nữa, dữ liệu thu thập được phải được làm sạch kỹ lưỡng do chứa nhiều yếu tố không cần thiết như quảng cáo, biểu tượng cảm xúc,…
- Sử dụng công cụ bên thứ ba
Một số nền tảng và phần mềm như Brandwatch, NetBase, Hootsuite hoặc Talkwalker cung cấp dịch vụ thu thập dữ liệu mạng xã hội theo từ khóa, chủ đề, thương hiệu hoặc sự kiện. Các công cụ này thường tích hợp khả năng phân tích và trực quan hóa dữ liệu ngay trong hệ thống.
- Thu thập dữ liệu bằng khảo sát
Dữ liệu định tính cũng có thể thu thập bằng các bảng khảo sát trực tuyến hỏi người dùng về hành vi sử dụng mạng xã hội, từ đó kết hợp với dữ liệu thực tế để đưa ra các phân tích sâu hơn.
Tùy theo mục tiêu nghiên cứu hoặc ứng dụng cụ thể, nhà phân tích cần lựa chọn phương pháp phù hợp, cân bằng giữa độ chính xác, tính hợp pháp và chi phí thu thập dữ liệu.
Phương pháp tinh chỉnh và làm sạch dữ liệu
Dữ liệu mạng xã hội thường nhiễu loạn, thiếu cấu trúc và không đồng nhất. Do đó, việc làm sạch và tiền xử lý dữ liệu là bước quan trọng trước khi phân tích hoặc đưa vào mô hình học máy. Các bước tinh chỉnh và làm sạch phổ biến gồm:
- Xử lý dữ liệu thiếu
Dữ liệu có thể thiếu do người dùng không cung cấp đầy đủ thông tin. Các kỹ thuật như loại bỏ dòng thiếu, thay thế bằng giá trị trung bình hoặc sử dụng mô hình học máy để ước lượng giá trị còn thiếu thường được áp dụng.
- Loại bỏ dữ liệu trùng lặp
Dữ liệu trùng lặp làm sai lệch kết quả phân tích. Việc phát hiện và loại bỏ các bản ghi trùng cần được thực hiện bằng so sánh nội dung và thời gian đăng tải.
- Làm sạch văn bản
Đối với dữ liệu văn bản, cần:
- Loại bỏ ký tự đặc biệt, emoji, URL, hashtag không cần thiết.
- Chuẩn hóa chữ hoa, chữ thường.
- Loại bỏ từ dừng (stop words).
- Chuyển các từ về dạng gốc (stemming, lemmatization).
- Xử lý ngôn ngữ tự nhiên (NLP)
Sau khi làm sạch, văn bản có thể được biến đổi thành dạng có thể phân tích bằng các kỹ thuật như:
- Vector hóa (TF-IDF, Bag-of-Words, Word2Vec).
- Trích xuất từ khóa.
- Phân tích cảm xúc.
- Gán nhãn chủ đề (topic modeling).
- Chuẩn hóa dữ liệu đa phương tiện
Với hình ảnh và video, cần trích xuất các đặc trưng như khuôn mặt, đối tượng, cảnh vật,… thông qua mạng nơ-ron tích chập (CNN) hoặc các mô hình học sâu khác.
Việc làm sạch dữ liệu không chỉ giúp nâng cao độ chính xác của phân tích mà còn cải thiện hiệu suất của các mô hình học máy hoặc thống kê sau này.
Phương pháp Tổng hợp
Sau khi thu thập và làm sạch dữ liệu, bước tiếp theo là tổng hợp để trích xuất thông tin giá trị.
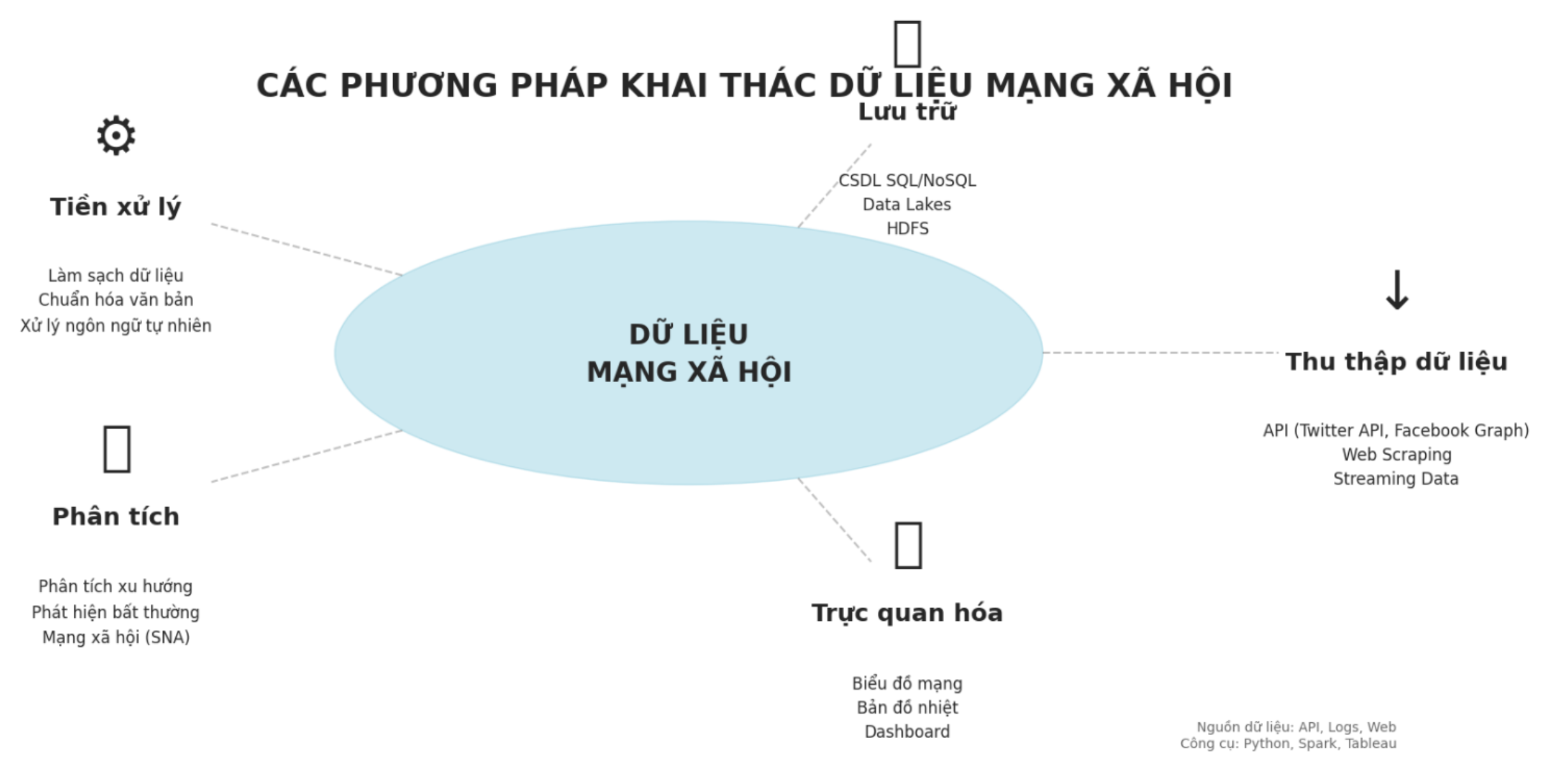
Các phương pháp tổng hợp dữ liệu mạng xã hội bao gồm:
- Phân tích thống kê mô tả
Cung cấp cái nhìn tổng quát về dữ liệu như số lượng bài viết theo thời gian, phân phối theo khu vực địa lý, tỷ lệ giới tính, độ tuổi,… Từ đó giúp nhận diện các mẫu hành vi nổi bật.
- Phân tích mạng xã hội (Social Network Analysis)
Dựa vào các mối quan hệ giữa người dùng để xây dựng mạng lưới và xác định các nút (node) có ảnh hưởng nhất. Một số chỉ số được sử dụng:
- Degree Centrality: Mức độ kết nối của một cá nhân.
- Betweenness Centrality: Vai trò trung gian trong luồng thông tin.
- Closeness Centrality: Mức độ gần gũi với tất cả các cá nhân khác.
- Phân tích cảm xúc (Sentiment Analysis): Giúp xác định thái độ tích cực, tiêu cực hoặc trung lập của người dùng đối với một chủ đề, thương hiệu hoặc sản phẩm. Đây là công cụ hữu hiệu trong đánh giá dư luận xã hội và hỗ trợ marketing.
-
Phân loại và phân cụm dữ liệu
- Phân loại (Classification): Sử dụng các thuật toán học máy như SVM, Naïve Bayes, Decision Tree để dự đoán loại bài đăng (ví dụ: tin tức, quảng cáo, phản hồi…).
- Phân cụm (Clustering): Nhóm các bài viết hoặc người dùng có đặc điểm tương đồng mà không cần nhãn trước, giúp phát hiện xu hướng hoặc cộng đồng ngầm ẩn.
- Dự đoán xu hướng (Trend Prediction): Thông qua mô hình chuỗi thời gian (ARIMA), học sâu (LSTM) hoặc phân tích các hashtag phổ biến, có thể dự đoán chủ đề sẽ “hot” trong tương lai gần.
- Trực quan hóa dữ liệu: Sử dụng biểu đồ, bản đồ nhiệt (heatmap), biểu đồ mạng, word cloud,… để trình bày kết quả phân tích một cách sinh động và dễ hiểu cho người ra quyết định.
Kết luận
Khai thác dữ liệu mạng xã hội là một lĩnh vực liên ngành hấp dẫn, kết hợp giữa công nghệ thông tin, khoa học dữ liệu và hiểu biết xã hội. Việc ứng dụng hiệu quả khai thác dữ liệu mạng xã hội giúp tổ chức nắm bắt nhu cầu thị trường, đánh giá hình ảnh thương hiệu, phát hiện khủng hoảng truyền thông và hiểu rõ khách hàng hơn bao giờ hết. Tuy nhiên, để đạt được hiệu quả cao, cần có sự đầu tư đúng mức vào hạ tầng, kỹ thuật xử lý dữ liệu và tuân thủ nghiêm ngặt các quy định pháp lý về bảo mật và quyền riêng tư.
Tham khảo: https://datareportal.com/
ThS. Vương Xuân Chí- K.CNTT