fit@ntt.edu.vn
fit@ntt.edu.vn 028 71080889
028 71080889
Vì sao Feature Engineering quan trọng hơn cả mô hình?
Trong thực tế, khi mới học Khoa học dữ liệu, sinh viên thường có xu hướng chạy theo thuật toán:
- Logistic Regression
- Random Forest
- XGBoost
- Neural Network
Nhiều người tin rằng: “Mô hình càng phức tạp thì kết quả càng tốt”. Tuy nhiên, trong các dự án dữ liệu thực tế, những nhà khoa học dữ liệu giàu kinh nghiệm đều thống nhất một điều: Chất lượng của đặc trưng (feature) quan trọng hơn độ phức tạp của mô hình. Một mô hình đơn giản + feature tốt có thể vượt xa một mô hình phức tạp + feature kém.
Thống kê trong ngành cho thấy khoảng 60–80% thời gian của một dự án Machine Learning được dành cho việc hiểu dữ liệu, xử lý dữ liệu và xây dựng đặc trưng, trong khi thời gian huấn luyện mô hình chỉ chiếm một phần nhỏ. Điều đó cho thấy Feature Engineering chính là “trái tim” của toàn bộ hệ thống học máy.
Feature là gì và Feature Engineering là gì?
Feature (đặc trưng) là các biến đầu vào mà mô hình sử dụng để học. Ví dụ:
- Tuổi, giới tính, thu nhập
- Số lần mua hàng
- Thời gian truy cập
- Văn bản bình luận
- Hình ảnh, âm thanh…
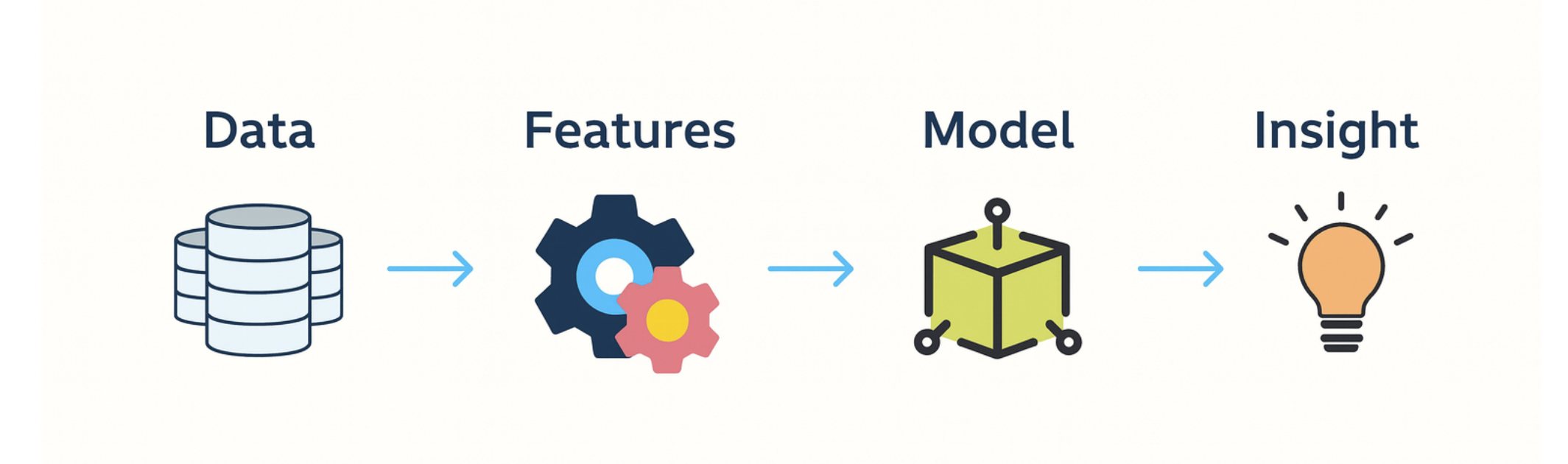
Feature Engineering là quá trình biến đổi dữ liệu thô → thành các đặc trưng có ý nghĩa → giúp mô hình học tốt hơn.
Nói một cách đơn giản, dữ liệu thô giống như nguyên liệu sống, Feature Engineering là quá trình chế biến, còn mô hình Machine Learning là người thưởng thức. Nếu “món ăn” – tức feature được chuẩn bị kém, thì dù mô hình có mạnh đến đâu, kết quả thu được cũng khó có thể tốt.Các nhóm Feature Engineering quan trọng trong thực tế
Xử lý dữ liệu số (Numerical Features)
Đây là nhóm feature phổ biến nhất, bao gồm:
- Tuổi
- Điểm số
- Doanh thu
- Số lượt truy cập
Các kỹ thuật xử lý thường dùng là chuẩn hóa dữ liệu để đưa các biến về cùng thang đo, xử lý giá trị thiếu bằng trung bình hoặc trung vị, đồng thời loại bỏ hoặc cắt ngưỡng các giá trị ngoại lệ. Nếu không xử lý tốt nhóm feature này, mô hình rất dễ học lệch, hội tụ kém và cho kết quả dự đoán không ổn định.
Xử lý dữ liệu phân loại (Categorical Features)
Dữ liệu phân loại thường gặp trong thực tế như:
- Giới tính: Nam/Nữ
- Khu vực: Bắc – Trung – Nam
- Loại khách hàng: Mới – Thân thiết – VIP
Do mô hình Machine Learning không xử lý trực tiếp được dữ liệu dạng chữ, các biến này cần được mã hóa sang dạng số bằng các phương pháp như Label Encoding, One-Hot Encoding, Target Encoding hoặc Embedding trong Deep Learning. Việc lựa chọn phương pháp mã hóa không phù hợp có thể làm số chiều dữ liệu tăng mạnh, gây nhiễu và khiến mô hình học sai bản chất.
Feature từ dữ liệu thời gian (Time-based Features)
Rất nhiều bài toán ngoài thực tế là dữ liệu theo thời gian:
- Doanh thu theo ngày
- Lượt truy cập theo giờ
- Giao dịch theo tháng
Từ cột thời gian, ta có thể tạo ra:
- Ngày – Tháng – Năm
- Thứ trong tuần
- Giờ cao điểm – thấp điểm
- Ngày lễ – ngày thường
Những feature này giúp mô hình nắm bắt được chu kỳ hoạt động, hiểu rõ xu hướng biến động và từ đó nâng cao độ chính xác dự đoán.
Feature từ dữ liệu văn bản (Text Features)
Dữ liệu văn bản xuất hiện khắp nơi:
- Bình luận khách hàng
- Đánh giá sản phẩm
- Nội dung học tập
- Email, tin nhắn
Các kỹ thuật phổ biến:
- TF-IDF
- Bag of Words
- Word Embedding (Word2Vec, FastText)
- Sentence Embedding (BERT, SBERT)
Nhờ các feature trích xuất từ dữ liệu văn bản, mô hình có thể thực hiện hiệu quả các bài toán như phân tích cảm xúc, phát hiện spam, hiểu ngữ nghĩa trong tìm kiếm và xây dựng các hệ thống chatbot thông minh.
Feature từ dữ liệu hành vi người dùng
Đây là nhóm feature đặc biệt quan trọng trong các hệ thống thương mại điện tử, giáo dục và mạng xã hội. Dữ liệu thường được khai thác từ số lần đăng nhập, thời gian sử dụng, lịch sử nhấp chuột và chuỗi hành động của người dùng. Từ đó có thể rút ra các đặc trưng phản ánh tần suất sử dụng, mức độ gắn bó và xu hướng hành vi, đóng vai trò quyết định trong độ chính xác của các hệ thống gợi ý, dự đoán rời bỏ và cá nhân hóa nội dung.
Feature tốt có thể “cứu” mô hình yếu
Trong thực tế, không hiếm trường hợp một mô hình Logistic Regression với feature được xây dựng tốt lại cho kết quả vượt XGBoost nhưng sử dụng feature kém. Tương tự, Random Forest với feature đúng bản chất vẫn có thể hoạt động hiệu quả hơn Deep Learning khi dữ liệu chưa được xử lý cẩn thận. Điều đó cho thấy bản thân mô hình không thể bù đắp cho dữ liệu kém chất lượng; một mô hình chỉ thực sự mạnh khi feature đúng bản chất, sạch và mang ý nghĩa thực tế.
Feature Engineering và Trí tuệ nhân tạo hiện đại
Trong Deep Learning và Generative AI, Feature Engineering không biến mất mà chỉ chuyển sang một hình thức khác, chẳng hạn như embedding trong xử lý ngôn ngữ, các đặc trưng tự học trong mạng CNN, Transformer hay việc vector hóa dữ liệu trong các hệ thống RAG. Dù mô hình có hiện đại đến đâu, dữ liệu đầu vào vẫn cần được làm sạch, gán nhãn chính xác và bảo đảm phân bố hợp lý. Nếu dữ liệu bẩn hoặc sai lệch, các mô hình sinh có thể “bịa” ra thông tin và dẫn đến những kết quả nghiêm trọng, khó kiểm soát trong thực tế.
Kết luận
Feature Engineering không phải là một bước phụ mà là nền móng của toàn bộ hệ thống Machine Learning. Một mô hình dù mạnh đến đâu cũng khó hoạt động hiệu quả nếu dữ liệu đầu vào sai lệch, feature kém chất lượng hoặc không phản ánh đúng bản chất bài toán. Trong kỷ nguyên AI và dữ liệu lớn, người làm Khoa học dữ liệu không chỉ xây dựng mô hình, mà còn phải hiểu sâu dữ liệu, chuyển dữ liệu thành tri thức và biến tri thức đó thành giá trị thực tế. Chính Feature Engineering là chiếc cầu nối quan trọng giữa dữ liệu thô và các hệ thống trí tuệ nhân tạo.