fit@ntt.edu.vn
fit@ntt.edu.vn 028 71080889
028 71080889

Dữ liệu là cứu cánh cho nhiều chuyên gia dữ liệu, chẳng hạn như nhà khoa học dữ liệu, kỹ sư và chuyên gia AI. Nếu không có dữ liệu, chúng ta không thể thực hiện công việc của mình một cách chính xác và mang lại giá trị cho doanh nghiệp.
Tuy nhiên, dữ liệu chúng tôi xử lý cũng phải hữu ích cho trường hợp sử dụng kinh doanh mà chúng tôi cố gắng giải quyết. Câu nói “garbage in, garbage out” có nghĩa là chúng ta sẽ nhận được đầu ra rác nếu chúng ta đưa dữ liệu rác vào. Đó là lý do tại sao chất lượng và nguồn gốc dữ liệu của chúng tôi sẽ quyết định chất lượng công việc của chúng tôi.

Là chuyên gia dữ liệu, chúng ta cần chú ý đến nơi chúng ta lấy dữ liệu vì các nguồn dữ liệu có thể có phạm vi bao phủ, định dạng, chi tiết, thiên vị và thông tin khác nhau để giải quyết vấn đề. Bài viết này sẽ khám phá các nguồn dữ liệu khác nhau mà bạn cần biết để giúp dữ liệu của bạn hoạt động.
Nguồn dữ liệu công khai và mở
Dữ liệu dễ dàng thu thập đầu tiên là bộ dữ liệu đã được công khai và miễn phí cho mọi người truy cập. Các nguồn này thường được duy trì bởi sự hỗ trợ của công chúng hoặc chính phủ vì lợi ích tốt nhất của họ là cung cấp các bộ dữ liệu đáng tin cậy cho công chúng.
Các nguồn dữ liệu mở rất quan trọng đối với nhiều chuyên gia dữ liệu vì chúng được ghi chép đầy đủ và quy mô lớn. Họ có thể cung cấp thông tin chi tiết hoặc dữ liệu đào tạo mà không có rào cản cấp phép. Hơn nữa, các nguồn dữ liệu mở, chẳng hạn như phát triển LLM, giúp cải thiện nghiên cứu dữ liệu trên toàn thế giới.
Có nhiều loại nguồn dữ liệu mở có sẵn, mà chúng ta sẽ khám phá dưới đây.
Dữ liệu mở của chính phủ
Chính quyền trung ương và địa phương thường công bố dữ liệu thống kê cho từng quốc gia để thúc đẩy tính minh bạch và thúc đẩy đổi mới trong nội bộ. Để cho phép công chúng truy cập vào những dữ liệu này, chính phủ thường tổng hợp chúng vào một cổng thông tin duy nhất, chẳng hạn như Data.gov và Dữ liệu mở của Liên minh châu Âu.
Ví dụ, đây là cổng thông tin Data.gov để truy cập tất cả dữ liệu mở của Chính phủ Hoa Kỳ đã được công bố.
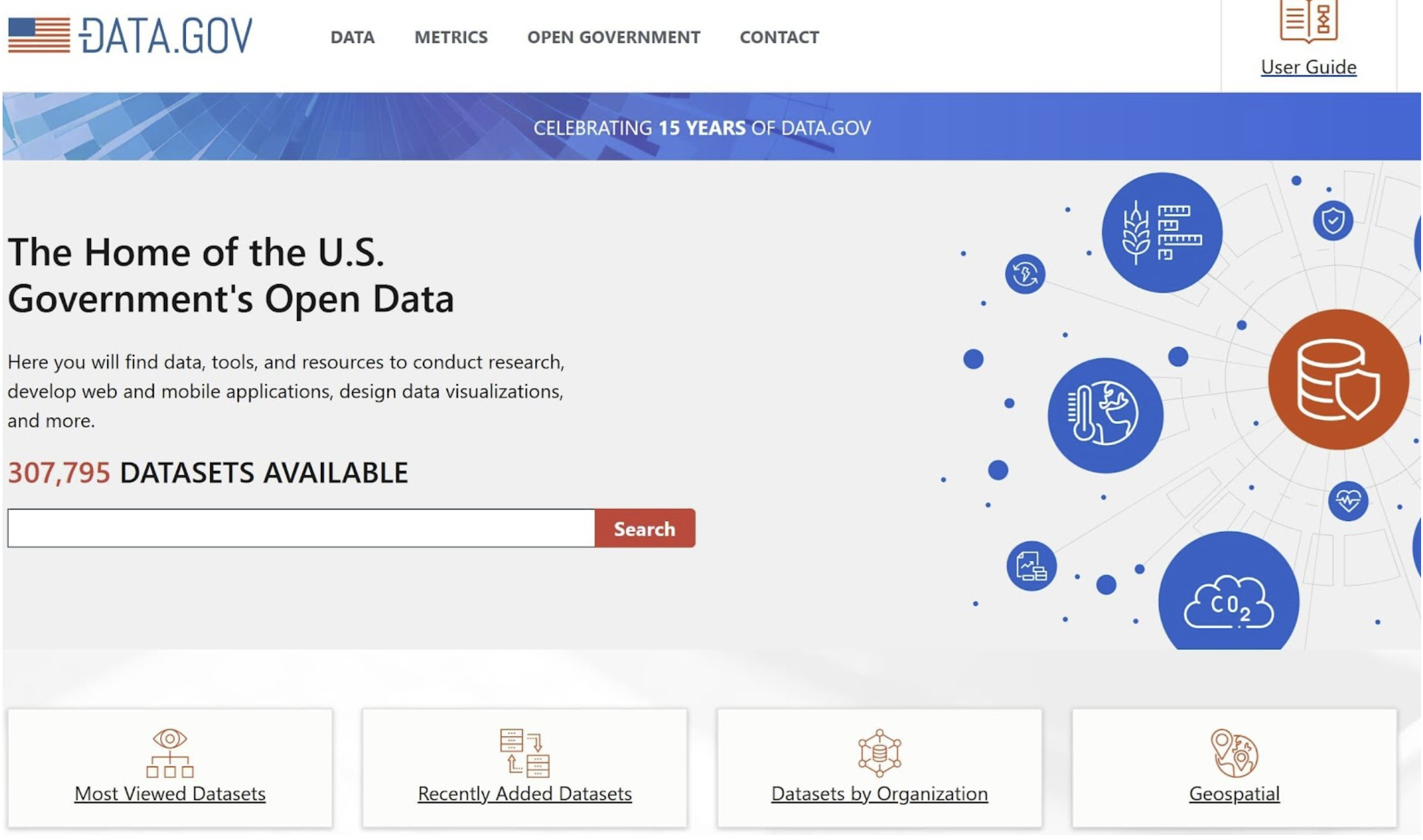
Các cổng thông tin này cung cấp quyền truy cập dễ dàng vào tất cả dữ liệu do chính phủ duy trì; bạn chỉ cần tìm kiếm dữ liệu hữu ích cho công việc của mình. Hãy xem điều gì sẽ xảy ra nếu bạn thấy các tập dữ liệu được xem nhiều nhất.
Tất cả các bộ dữ liệu có sẵn đều có mặt để chúng tôi có được và sử dụng. Hãy xem liệu chúng ta có chọn một trong các liên kết tập dữ liệu hay không.
Tất cả thông tin chúng ta cần về dữ liệu và nguồn của nó được tổng hợp trên một trang. Với mức độ thông tin và dễ dàng thu thập dữ liệu, dữ liệu mở của chính phủ là nguồn dữ liệu mà chúng ta không thể bỏ lỡ.
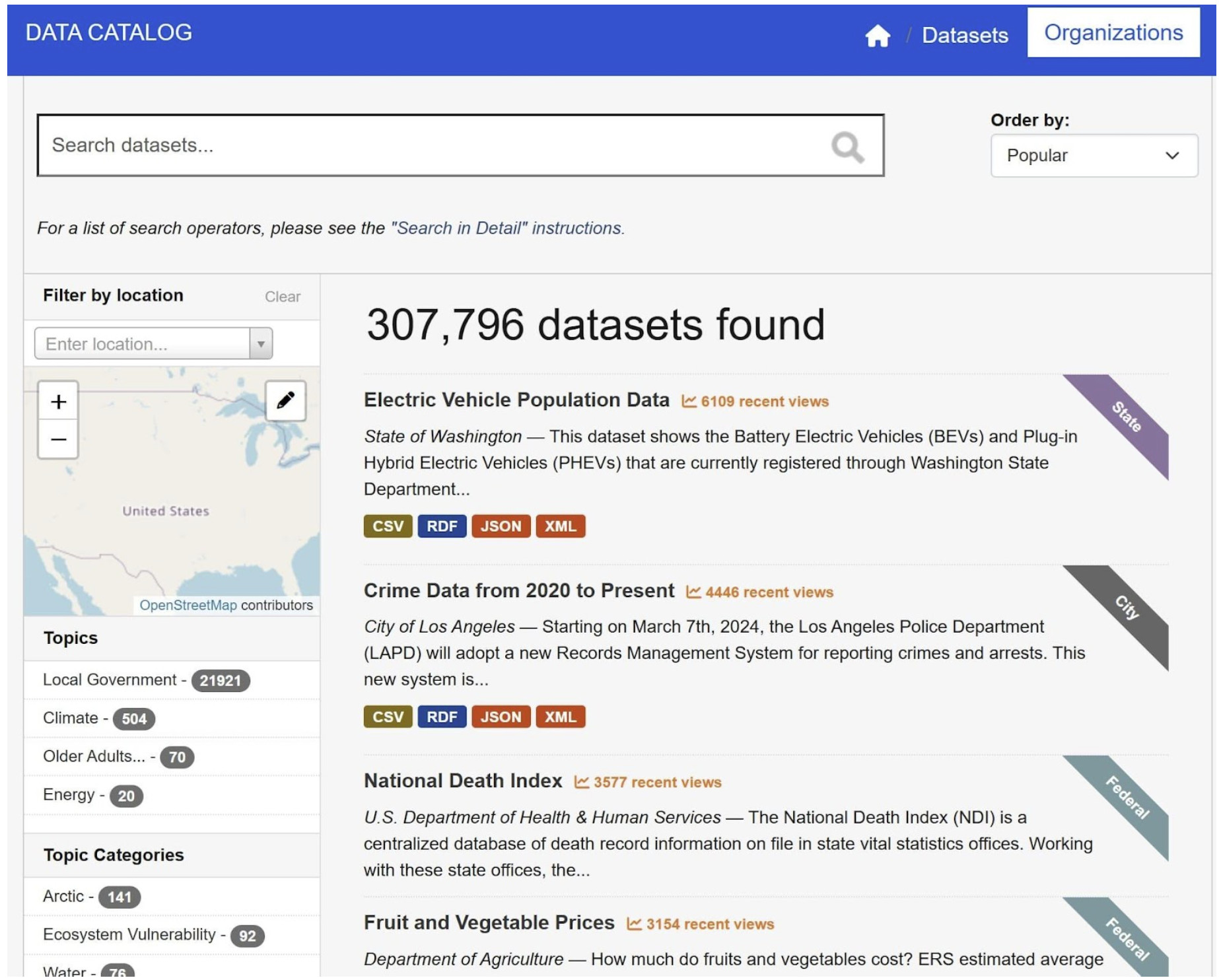
Nguồn dữ liệu nghiên cứu và cộng đồng
Chính phủ không chỉ duy trì các nguồn dữ liệu mở, mà nhiều nhóm nghiên cứu và cộng đồng cũng vậy. Các nguồn này thường được truy cập miễn phí và cung cấp nhiều loại hơn dữ liệu của chính phủ. Tuy nhiên, vì công chúng duy trì chúng, chúng ta vẫn phải xác nhận chất lượng và giấy phép sử dụng của chúng.
Nhiều ví dụ về nghiên cứu và nguồn dữ liệu cộng đồng bao gồm Kaggle, Kho lưu trữ học máy UCI, Bộ dữ liệu khuôn mặt ôm, v.v.
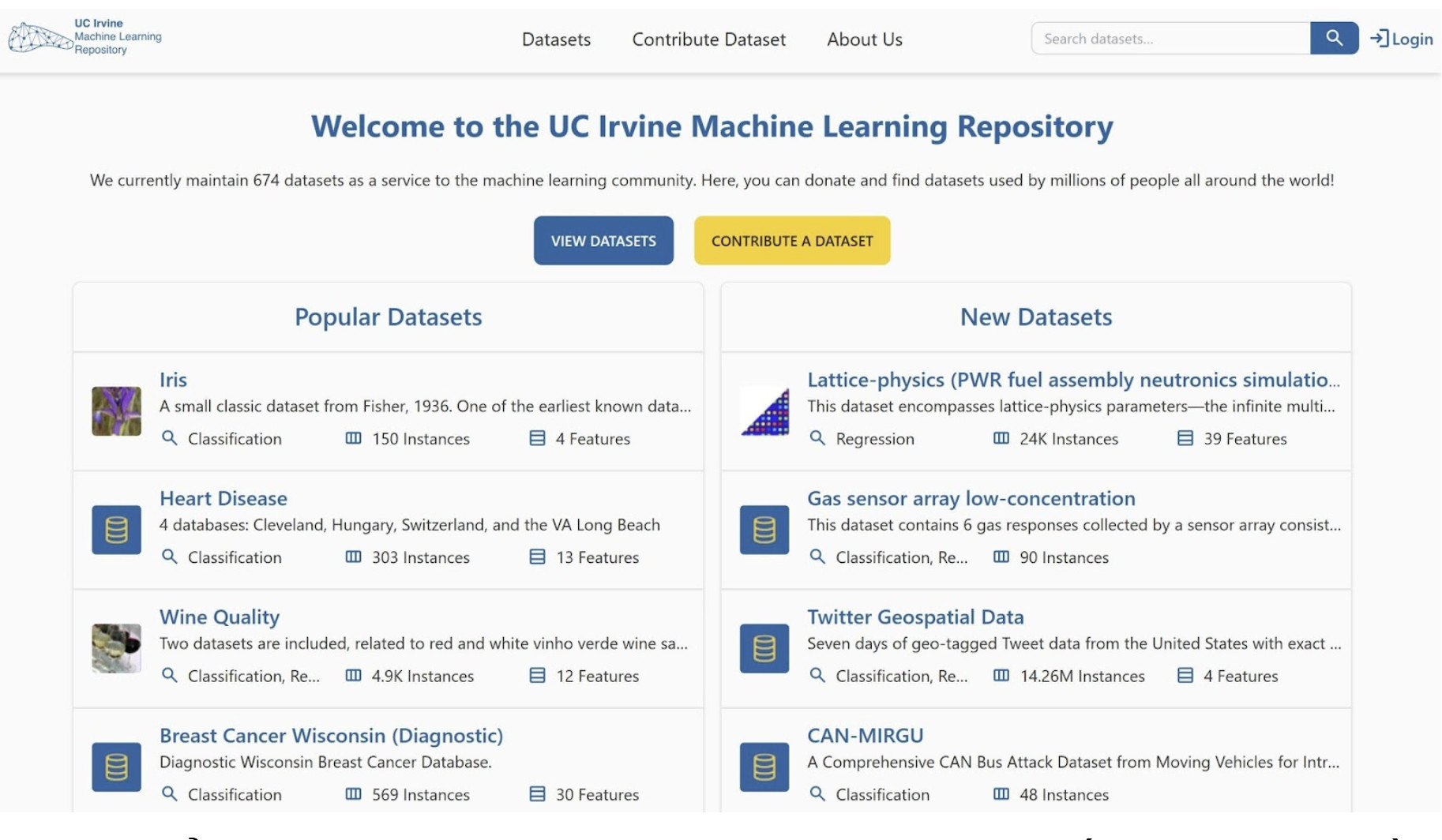
Ví dụ: UCI Machine Learning Repository hiển thị tất cả các bộ dữ liệu công khai mở mà chúng ta có thể sử dụng trên trang web của họ.
Bạn có thể chọn một trong các bộ dữ liệu và thu thập tất cả thông tin cần thiết, bao gồm cả việc tải xuống tập dữ liệu.
Kaggle cũng không khác vì nó lưu trữ một bộ dữ liệu mở; tuy nhiên, dữ liệu chủ yếu đến từ công chúng và mọi người cũng có thể tải lên dữ liệu của họ. Truy cập trang tập dữ liệu của họ để tìm tất cả các bộ dữ liệu của cộng đồng và thêm dữ liệu của bạn.
Nguồn dữ liệu cộng đồng và nghiên cứu mở là nơi tốt nhất để bạn có được bộ dữ liệu trong các lĩnh vực khác nhau mà khó tìm thấy bằng cách khác.
Tổ chức quốc tế
Nhiều tổ chức quốc tế duy trì các nguồn dữ liệu cho các trường hợp sử dụng khác nhau, chẳng hạn như kinh tế, y tế và dân số. Ví dụ về các tổ chức toàn cầu có nguồn dữ liệu mở bao gồm Dữ liệu mở của Ngân hàng Thế giới và Tổ chức Y tế Thế giới (WHO).
Dữ liệu mở của Ngân hàng Thế giới cho phép chúng tôi tìm kiếm và tải xuống các dữ liệu khác nhau liên quan đến phát triển toàn cầu.
Bộ dữ liệu ở đây tương tự như nguồn dữ liệu của tổ chức chính phủ, nhưng nó được kiểm soát và duy trì bởi một nhóm quốc tế chứ không phải một quốc gia riêng lẻ.
API để truy cập dữ liệu
API đã đóng một vai trò quan trọng như một nguồn dữ liệu trong thời đại dữ liệu hiện nay. Nhiều công ty và nền tảng hiển thị API của họ, cho phép công chúng truy xuất dữ liệu theo yêu cầu. Cách tiếp cận này cho phép tích hợp dữ liệu theo thời gian thực và dễ quản lý hơn nhiều so với tải xuống các tệp tĩnh.
API truyền thông xã hội
Nhiều phương tiện truyền thông xã hội nổi tiếng cung cấp API để các nhà phát triển truy cập nội dung công khai được chia sẻ trên nền tảng của họ. Ví dụ: X và Reddit cung cấp các API mà chúng tôi có thể dễ dàng sử dụng để lấy dữ liệu đó.
Ví dụ: tài liệu API dành cho nhà phát triển X giúp chúng tôi điều hướng và thu thập dữ liệu cần thiết.
Với X API, bạn có thể nhận dữ liệu về các bài đăng công khai, người dùng, mức độ tương tác và nhiều dữ liệu khác. Sử dụng chúng một cách khôn ngoan, vì dữ liệu cá nhân vẫn có sẵn cho công chúng.
API dữ liệu tài chính
Ngay cả khi không mua dữ liệu thương mại, người ta có thể sử dụng các API công khai để có sẵn dữ liệu tài chính thông qua các API tài chính. Dữ liệu như giá cổ phiếu và thông tin tài chính của công ty thường đã được hiển thị trên nền tảng công khai, nhưng việc thu thập chúng trong thời gian thực có thể yêu cầu triển khai API.
Những API nổi bật là API dữ liệu tài chính, bao gồm Yahoo Finance API và Alpha Vantage. Dưới đây là các nền tảng Alpha Vantage để thu thập dữ liệu tài chính.
Bạn có thể yêu cầu khóa API miễn phí, khóa này bạn có thể sử dụng để truy cập tất cả dữ liệu tài chính cho bất kỳ ứng dụng kinh doanh nào bạn cần.
API không gian địa lý
Một nguồn dữ liệu khác mà chúng ta có thể sử dụng là API không gian địa lý. Dữ liệu không gian địa lý là dữ liệu liên quan đến vị trí địa lý, chẳng hạn như địa chỉ tọa độ, giao thông, thông tin địa chỉ và nhiều thứ khác. Những dữ liệu này hữu ích cho nhiều trường hợp sử dụng kinh doanh, đặc biệt nếu chúng tôi đang làm việc với vị trí địa lý.
Chúng ta có thể truy cập API không gian địa lý bằng một số nền tảng, bao gồm API Google Maps hoặc OpenStreetMap. Các nền tảng tương ứng duy trì các dữ liệu này và có tiêu chí truy cập riêng.
Ví dụ: chúng ta có thể lấy các khóa API để truy cập API Google Maps thông qua Google Cloud Platform của họ.
Hãy thử thử với các API để xem liệu dữ liệu cần thiết của bạn có sẵn hay không.
Dữ liệu tổng hợp
Đôi khi, dữ liệu bạn cần không tồn tại hoặc không thể được sử dụng do lo ngại về quyền riêng tư — đây là lúc dữ liệu tổng hợp xuất hiện. Dữ liệu tổng hợp nhằm mục đích tạo ra một bộ dữ liệu trông hoặc bắt chước thực tế (thống kê hoặc cấu trúc) và có thể được sử dụng tự do.
Chúng tôi sử dụng dữ liệu tổng hợp trong nhiều tình huống, bao gồm cả trường hợp dữ liệu chính xác cho các vấn đề kinh doanh cụ thể khan hiếm hoặc mất cân bằng. Trong thời đại của AI tổng hợp, nó thậm chí còn trở nên phổ biến hơn vì việc có được đủ dữ liệu đào tạo cho các mô hình là một thách thức. Có nhiều khả năng để có được dữ liệu tổng hợp.
Có nhiều cách để thu thập dữ liệu tổng hợp, chẳng hạn như sử dụng LLM, thuật toán mã nguồn mở hoặc cách tiếp cận thương mại. Mỗi loại đều có lợi thế hơn cái kia.
Ví dụ: có thể sử dụng Trình tạo dữ liệu tổng hợp miễn phí sử dụng LLM từ Argilla được lưu trữ trong Không gian Hugging Face.
Sử dụng trình tạo ở trên, chúng ta có thể tạo một bộ dữ liệu tổng hợp bắt chước thế giới thực và hữu ích cho các hoạt động tiếp theo.
Kết luận
Dữ liệu là dòng máu của bất kỳ chuyên gia dữ liệu nào, vì chúng tôi không thể thực hiện công việc của mình nếu không có nó. Việc thu thập dữ liệu chất lượng và liên quan sẽ trở nên cần thiết trước khi bất kỳ hoạt động tiền xử lý nào xảy ra.
Nguồn: Cornellius Yudha Wijaya, Chuyên gia nội dung kỹ thuật KDnuggets vào ngày 24 tháng 3 năm 2025 trong Khoa học dữ liệu
Các nguồn dữ liệu phổ biến
Public sector data
- UCI Machine Learning Repository: https://archive.ics.uci.edu/
- US government: https://www.data.gov
- UK government: https://data.gov.uk
- EU: https://www.europeandataportal.eu
- CIA World Fact Book: https://www.cia.gov/library/publications/the-world-factbook/
- Health data (over 125 years): https://www.healthdata.gov/
Data registries
- Datasets hosted on Amazon AWS https://registry.opendata.aws
- Million Song Dataset, 1000 Genome Project, database of satellite imagery of Earth from
- NASA, Web Crawl
- Google’s Dataset Search: https://datasetsearch.research.google.com/
- Microsoft Datasets: https://msropendata.com/
- Dataset collection on Github: https://github.com/awesomedata/awesome-public-datasets
- Data Hub: http://datahub.io
- Linked Open Data Cloud: http://lod-cloud.net/
Knowledge graphs
- Wikidata: https://www.wikidata.org
- BabelNet: https://babelnet.org
- DBpedia: http://wiki.dbpedia.org
Language resources
- WordNet: https://wordnet.princeton.edu
- EuroWordNet: http://projects.illc.uva.nl/EuroWordNet/
- Project Gutenberg (36.000 ebooks): http://www.gutenberg.org/
- New York Times (starts 1851): http://developer.nytimes.com/docs
- Wikitionary: https://www.wiktionary.org as KG: http://kaiko.getalp.org/about-dbnary/
Competitions
- Kaggle: https://www.kaggle.com/
ThS. Sử Nhật Hạ- KCNTT