


ĐỊNH LÝ BAYES – VÀ ỨNG DỤNG VÀO BÀI TOÁN LỌC THƯ RÁC
Ngày đăng: 10/05/2023
Ứng dụng Định lý Bayes và học máy (machine learning) kết quả đã xác định định Email 11 là một Email Spam
-
Đặt vấn đề:
Với sự nổi lên nhanh chóng của trí tuệ nhân tạo hiện nay, việc tiếp cận bằng học máy (machine learning) đã trở thành một thuật ngữ rất quen thuộc với mọi người. Học máy đã đang và sẽ được ứng dụng trong vô số ứng dụng hiện nay trong nhiều lĩnh vực như việc dự đoán rủi ro trong kinh tế, phân loại tin nhắn trong các công cụ như Gmail hay Yahoo hay gần đây là ứng dụng chẩn đoán bệnh trong y tế ,... Vậy với những người quan tâm về cách máy tính có thể dự đoán được ra kết quả, dựa vào từ 1 tập dữ liệu đầu vào. Bài viết này tác giả sử dụng Định lý Bayes trong Xác suất thống kê cùng với phương pháp học máy (Machine learning) để phân loại mail Spam hay Not Spam và demo bằng ngôn ngữ Python.
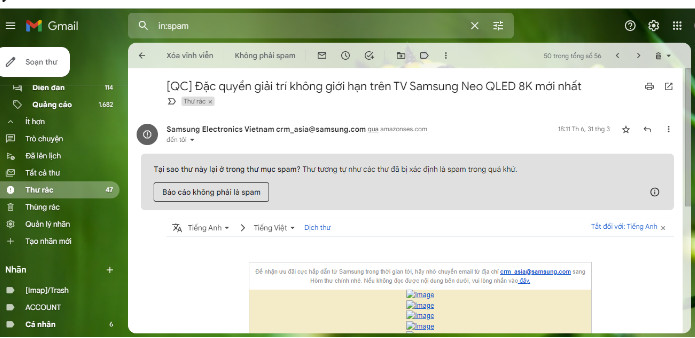
-
Phương pháp:
Suy diễn Bayesian là một kiểu suy diễn đơn giản mà máy tính dựa vào các xác suất của dữ liệu đã có trước của bài toán để tìm ra xác suất của đầu ra cho những đầu vào tiếp theo.
Công thức Bayes:
P(A|B) = P(A).P(B|A)/P(B)
- P(A): Xác suất của sự kiện A xảy ra
- P(B ): Xác suất của sự kiện B xảy ra
- P(B|A): Xác suất (có điều kiện) của sự kiện B xảy ra, nếu biết rằng sự kiện A đã xảy ra
- P(A|B): Xác suất (có điều kiện) của sự kiện A xảy ra, nếu biết rằng sự kiện B đã xảy ra
Các phương pháp suy diễn dựa trên xác suất sẽ sử dụng xác suất có điều kiện.
Cụ thể hơn, Baysian được xây dựng và dựa vào công thức dưới đây để tính rồi so sánh các kết quả lại với nhau để biết xác suất nào là cao hơn
y = cMAP = argmaxP(cj|x1,x2,…,xn) với cj thuộc C
C là tập nhãn có thể nhận được của y (trong trường hợp này C là tập gồm 2 giá trị Spam và Not Spam)
Nhìn lại một chút, công thức trên của Bayesian có nghĩa là chúng ta sẽ tính tất cả các xác suất của từng nhãn khi đã biết sự xảy ra hoặc không xảy ra các thuộc tính cho trước (x1, x2, ..) rồi chọn lấy giá trị lớn nhất (argmax) và đó cũng chính là kết quả dự đoán của chúng ta.
Vấn đề ở chỗ, xác suất xảy ra của nhãn khi biết các điều kiện khác (Xác suất mail là Spam khi biết x1 = vay tiền, x2 = Tour du lịch, x3 = Samsung Electronics… ) là điều mà ta đang cần biết, vậy nên công thức trên có thể được viết lại:
y = argmaxP(x1,x2,…,xn|cj)P(cj)
P(cj) ở đây được tính là tần suất xuất hiện của nhãn trên toàn bộ tập dữ liệu và có thể được tính rất dễ dàng, ví dụ ở trong bài toán của chúng ta đang nói P(Spam) = P(Not Spam)=50/100
Vấn đề khó khăn hơn ở việc tính xác suất P(x1,x2,…,xn|cj)P(cj)
- Xác suất xảy ra đồng thời các điều kiện x1,x2,…,xn khi nhãn cj xảy ra. Thông thường việc tính này là bất khả thi (nhất là khi số lượng điều kiện n là lớn). Vậy nên thông thường, chúng ta sẽ coi các xác suất x1,x2,..xn là độc lập với nhau, từ đó
P(x1,x2,…,xn|cj) = P(x1|cj).P(x2|cj)…P(xn|cj)
P(x1|cj) được tính dựa trên tập dữ liệu có trước đó bằng số lần xi xuất hiện cùng với cj chia cho tổng số lần xi xuất hiện
Tóm lại bộ phân loại Bayes đơn giản sẽ được viết như sau:
y = argmaxP(cj)TichP(xi|cj)
-
Thuật toán:
Ta có training data gồm 10 email đánh dấu 2 nhãn (Label): Spam (S) và Not Spam (N)
Bảng từ vựng như sau:
X = [x1, x2, x3, x4, x5]
Trong đó: w1 = vay tiền, w2 = Tour du lịch, w3 = Samsung Electronics, w4 = Đang tuyển dụng, w5 = Bán hàng.
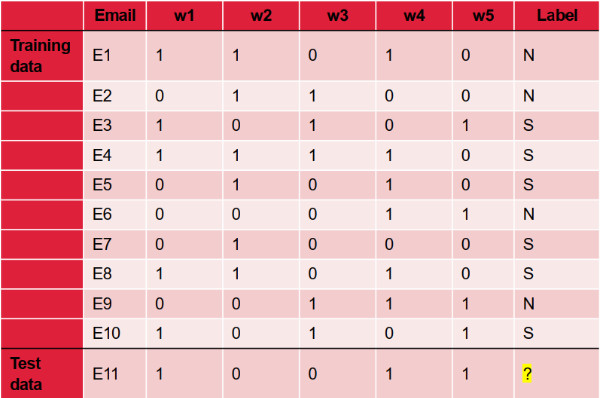
Vấn đề đặt ra: Cho biết email 11 là Spam hay Not Spam?
import math #pip install scikit-learn
from sklearn.naive_bayes import BernoulliNB #thư viện hàm Bayes
import numpy as np #train data –huan luyen du lieu;
e1 = [1, 1, 0, 1, 0]
e2 = [0, 1, 1, 0, 0]
e3 = [1, 0, 1, 0, 1]
e4 = [1, 1, 1, 1, 0]
e5 = [0, 1, 0, 1, 0]
e6 = [0, 0, 0, 1, 1]
e7 = [0, 1, 0, 0, 0]
e8 = [1, 1, 0, 1, 0]
e9 = [0, 0, 1, 1, 1]
e10 = [1, 0, 1, 0, 1]
train_data = np.array([e1, e2, e3, e4, e5,
e6, e7, e8, e9, e10])
label = np.array(['N', 'N', 'S', 'S', 'S', 'N',
'S', 'S', 'N', 'S'])
e11 = np.array([[1, 0, 0, 1, 1]])
#test data –du lieu can test
clf1 = BernoulliNB(alpha=1e-10)
clf1.fit(train_data, label)
BernoulliNB(alpha=1e-10, binarize=0.0,
class_prior=None, fit_prior=True)
#Huấn luyện (phân tích, xử lý ..)
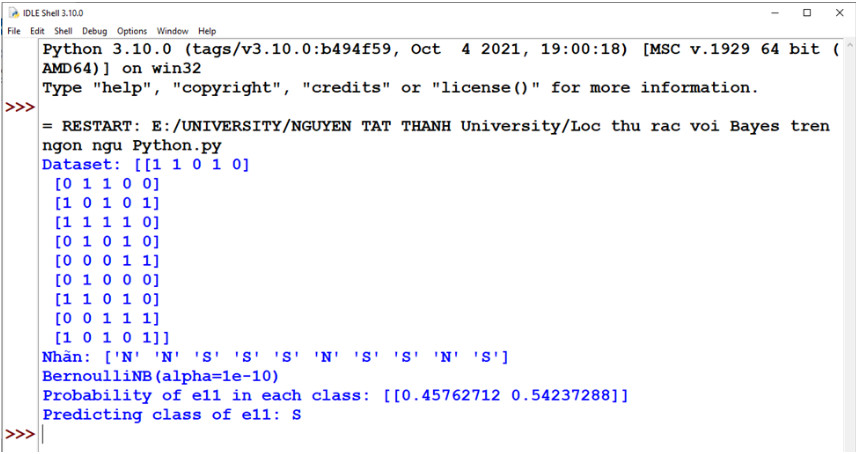
print('Probability of e11 in each class:',
clf1.predict_proba(e11))
Probability of e11 in each class: [[0.45762712
0.54237288]]
#tính xác suất
print('Predicting class of e11:',
str(clf1.predict(e11)[0]))
Predicting class of e11: S
-
Kết luận:
Ứng dụng Định lý Bayes và học máy (machine learning) kết quả đã xác định định Email 11 là một Email Spam
Lễ trao giải "Khoảnh khắc IT" Khoa Công nghệ thông tin 2024 - 23/11/2024
5 lời khuyên hàng đầu cho việc học máy học (Phần 4) - 07/11/2024
Phát động cuộc thi "KHOẢNH KHẮC IT" Khoa Công nghệ thông tin - 31/10/2024
Các gói học máy Python hàng đầu (Phần 3) - 17/10/2024
Báo cáo Thực tập tốt nghiệp của Sinh viên khóa 2020 Ngành CNTT - 19/09/2024
Cách học Machine Learning từ đầu vào năm 2024 (Phần 2)- 13/09/2024
Cách học Machine Learning vào năm 2024 (Phần 1)- 16/08/2024
Thông báo cuộc thi Khoa học dữ liệu Khoa Công nghệ thông tin Tháng 8/2024- 12/07/2024
Thông báo cuộc thi "Trí tuệ nhân tạo Khoa CNTT năm 2024"- 16/06/2024
Cuộc thi Ý tưởng Khởi nghiệp Sinh viên UNIV. STAR 2024- 14/06/2024




13/08/2024
Kế hoạch Thực tập tốt nghiệp Ngành Công nghệ thông tin, Ngành kỹ thuật phần mềm và Ngành Mạng máy tính và Truyền thông dữ liệu - HK1 Năm học 2024 - 202531/05/2024
Kế hoạch thực tập tốt nghiệp Ngành CNTT - HK3 Năm học 2023 - 202416/05/2024
THÔNG BÁO: THỜI GIAN VÀ ĐỊA ĐIỂM + DANH SÁCH HỘI ĐỒNG BÁO CÁO KHOÁ LUẬN TỐT NGHIỆP22/11/2022
Hệ thống MegaSchool và MegaTest thông báo tuyển dụng Thực tập sinh
13/07/2022
TMA Solutions - Cơ hội việc làm dành cho sinh viên Khoa CNTT
04/07/2022
10/06/2022
T UYỂN DỤNG NHÂN VIÊN HÀNH CHÍNH IT– TEXGAMEX-VN
16/05/2022
Thông tin tuyển dụng công ty PORTLOGICS - PLC
15/04/2022
Ngân hàng Á Châu (ACB) tuyển Chuyên viên Dịch vụ IT – Hồ Chí Minh





